Fuzzing for known vulnerabilities with Rode0day pt 2
Improving fuzzer code coverage
This is a follow on post to my first article where we went over setting up the American Fuzzy Lop fuzzer (AFL)written by Michał Zalewski. When we previously left off our fuzzer was generating test cases for the Rode0day beta binary buffalo.c available here. However we quickly found out that the supplied input file didn’t appear to be enough to generate many code paths. Meaning we weren’t testing many new instruction sets or components of the application. A very simple explanation of a code path can be found here.
Unfortunately for us the challenge provided an arbitrary file parser for us to fuzz, in the case of fuzzing something like a pdf parser we would have a large corpus available to us out on the internet to download and start fuzzing with. In the case of fuzzing something like the PDF file format you wouldn’t even need to understand anything about the file format to begin fuzzing!
Yet another setback is that there is no documentation, most standardized file formats follow a spec, such that there will be interoperability between different applications opening the same file. This is why you can read a pdf file in your web browser, adobe reader, foxit reader etc. If you are interested the pdf spec is available here.
While we don’t have the spec for the buffalo file format parser we do have the C source code available, which is the next best thing. I am not an experienced C developer but looking at the source code for a few minutes and a few things become apparent. At a number of lines we can see that there are multiple calls to printf:
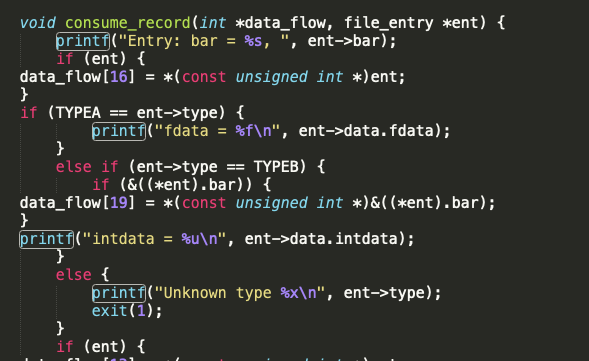
Printf can be used in unsafe ways to leak data from the stack, or worse. In this case it doesn’t look immediately exploitable, but our fuzzing will help us determine if that is the case or not.

Here printf is printing the string “file timestamp” then printing an unsigned decimal (unsigned int) head.timestamp. “head timestamp” appears to be part of an element in the data_flow array.
Nevertheless the point of this challenge is to fuzz the binary not reverse engineer it. For the purpose of the challenge we would want to understand what kind of input the program is expecting to parse. While reading the beginning of the source code two things immediately stand out. The format for the file_header is described as well as the file_entry struct
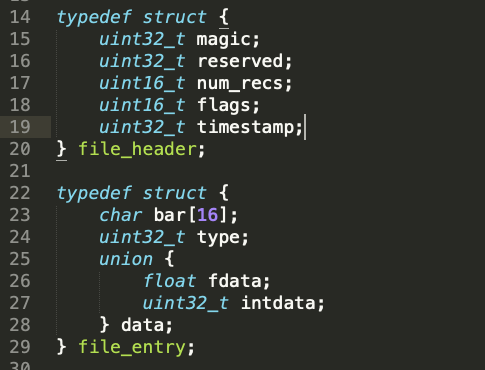
Then we see that like a lot of file formats the program checks to see if there is a specific file format header or “magic bytes” when beginning to parse the file.
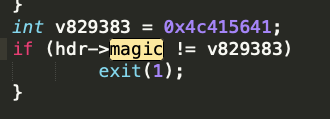
Here the value in int v829383 is set to 0x4c415641. If the 0x41 looks familiar thats good because that is letter “A” in ASCII. Thus the magic bytes in ASCII is the string “LAVA” so based on this information we can say that the contest organizers didn’t even give us a file format that can be fully parsed by the application! let’s create some valid files!
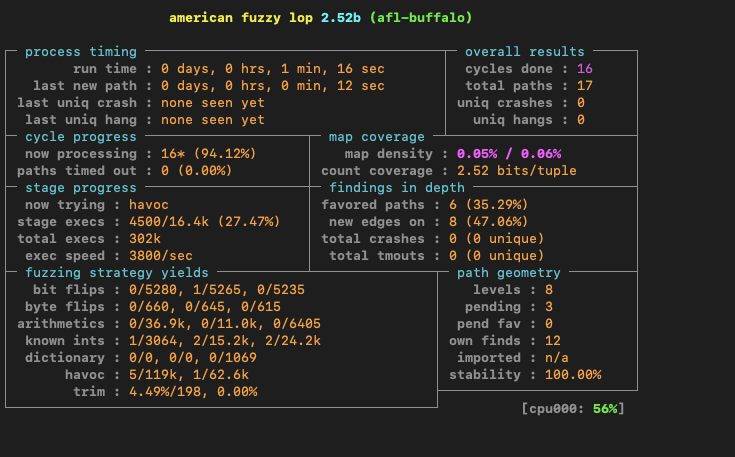
Once we point AFL to our corpus directory and start another fuzzing run we immediately see new paths being explored by AFL. In the prior blog post after running AFL for some time there were only 2 paths explored. This would make sense because after examining the source code we discovered that the sample file provided to us would immediately get rejected by the program since it didn’t have the correct magic bytes. So beforehand the only path we explored was the magic byte check in the code, then no other paths were explored.
Diving deeper into the code we can work on writing an input file with a proper file_header and file_entry structs such that we would exercise the normal code paths of the application and not the error handling paths. Below i’ve copied the struct code and added the strings that I think will match what the structs are expecting.
typedef struct {
uint32_t magic; =“AVAL”
uint32_t reserved; = “AAAA”
uint16_t num_recs; = “AA”
uint16_t flags; = “AA”
uint32_t timestamp; “AAAA”
} file_header;
typedef struct {
char bar[16]; = “DDDDDDDDDDDDDDDDDD”
uint32_t type; = “AAAA”
union {
float fdata; "0.0"
uint32_t intdata; "1"
} data; "data"
} file_entry;
based on the struct definitions something like:
echo “AVALAAAAAAAAAAAADDDDDDDDCCCCCCCCAAAAAAAA” > ./samples/test.poc
should create a file that parses and it does to a certain extent.

The above file would be great to add to a sample corpus, using the source code as our guide we can create a number of additional input files to test new code paths. I spent some time working to create additional sample files with quite a bit of success in discovering new paths. Compared with the original post I was able to uncover 127 total code paths in a few hours of fuzzing.
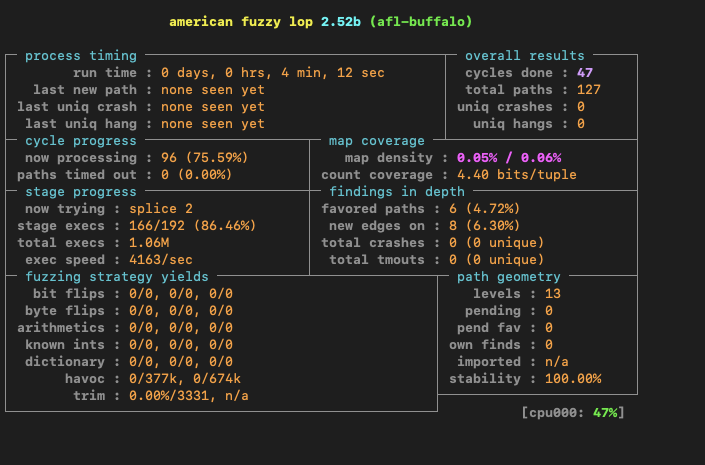
If you’d like some hints on what other input files to provide to the application I’ve included a number of input files here. Be warned there are a number of crashing inputs to the binary so you will have to remove them before AFL will begin the run. Good luck and happy fuzzing!